Uptime, stability, performance, scalability. These are all operational priorities within a content delivery context. Nowadays, people have little tolerance for downtime, or even small hiccups in terms of stability.
Maintaining operational stability requires scaling out your infrastructure. As explained early on in the book: Varnish operates as an origin shield. It takes away a lot of load from the origin servers.
But even with Varnish protecting your origin layer, there is still a need to scale your infrastructure. You’ll need at least two Varnish servers to ensure continuity if one of your Varnish servers were to go down.
This concept of taking precautions in case of individual failures is what we call high availability: you plan for failure, and you make sure fallback servers can take over when required.
A lot of high availability strategies have an active-passive setup, where only a part of the infrastructure is used at all times. In this case, a certain percentage of your infrastructure is only used when a failover needs to happen.
There’s a level of inefficiency there, and a lot of companies are improving the inefficiency by opting to use active-active setups, where traffic is routed to all nodes.
An added benefit of scaling out for high-availability reasons is the fact that you’re also scaling out for performance reasons: because you have a load-balanced setup with multiple Varnish nodes, you’ll be able to handle a lot more traffic.
One of the challenges when dealing with multiple Varnish servers is keeping the caches hot. When a node fails, and the fallback server is cold, you’ll start off with a lot of cache misses, which can have an immediate impact on the origin.
A cache is cold when it has expired, is minimal or has no content.
Making sure your caches are synchronized avoids an additional strain on the origin. That is, if your load balancer does round-robin distribution, it is possible that a hit from the previous request now turns into a miss because the current node doesn’t have the object in cache.
There are solutions out there where Varnish servers are chained to each other and act as each other’s backend. There is some additional detection logic in there to avoid loops, but all in all this is sub-optimal, and not a real HA solution.
Varnish Enterprise comes with a full-blown high-availability suite called Varnish High Availability. But we’ll just refer to it as VHA.
VHA will replicate cache inserts on one Varnish server to the other nodes in the cluster. The request that resulted in a miss and triggered the broadcast on the first node will now result in a cache hit when the equivalent request is received by the other servers in the cluster.
The VHA logic is written in VCL, requires a couple of VMODs, and primarily depends on the Varnish Broadcaster for replication.
A key aspect of VHA is performing the actual replication, and knowing which servers to send the data to. Instead of opting for a custom implementation, the Varnish Broadcaster was chosen as the replication mechanism.
The broadcaster is already an important tool in the Varnish Enterprise toolbox. As discussed in chapter 6, the broadcaster is commonly used to perform cache invalidations on multiple Varnish servers. In essence the broadcaster’s main role is in its name: broadcasting HTTP messages.
In VHA, the broadcaster will broadcast replication messages containing information about the inserted object. The exact details will be discussed when we talk about the architecture.
Another feature of the broadcaster is the nodes.conf file that
contains the server inventory of the Varnish cluster. If you use the
broadcaster, you’re already using nodes.conf, which means you
already defined the nodes in your cluster.
This concept can also be reused for VHA: it is very likely that the inventory that is used for cache invalidation will also be used for replication.
The broadcaster can either be hosted on your individual Varnish servers, or you can have a set of dedicated broadcaster servers that Varnish connects to.
The way VHA interacts with the broadcaster can be configured. We’ll cover this later in this section about VHA.
As mentioned, the broadcaster does a lot of the heavy lifting in VHA. The logic that decides what, when, and how broadcasting happens, is written in VCL.
The Varnish instance that initiates the replication is called the VHA origin. Yes, that may sound confusing because we have always called our backend servers the origin. But in the VHA context, the origin is the Varnish server that initiates the broadcast.
The server that receives the replication request is called the VHA peer.
As you can see in the diagram below, VHA has a specific workflow:
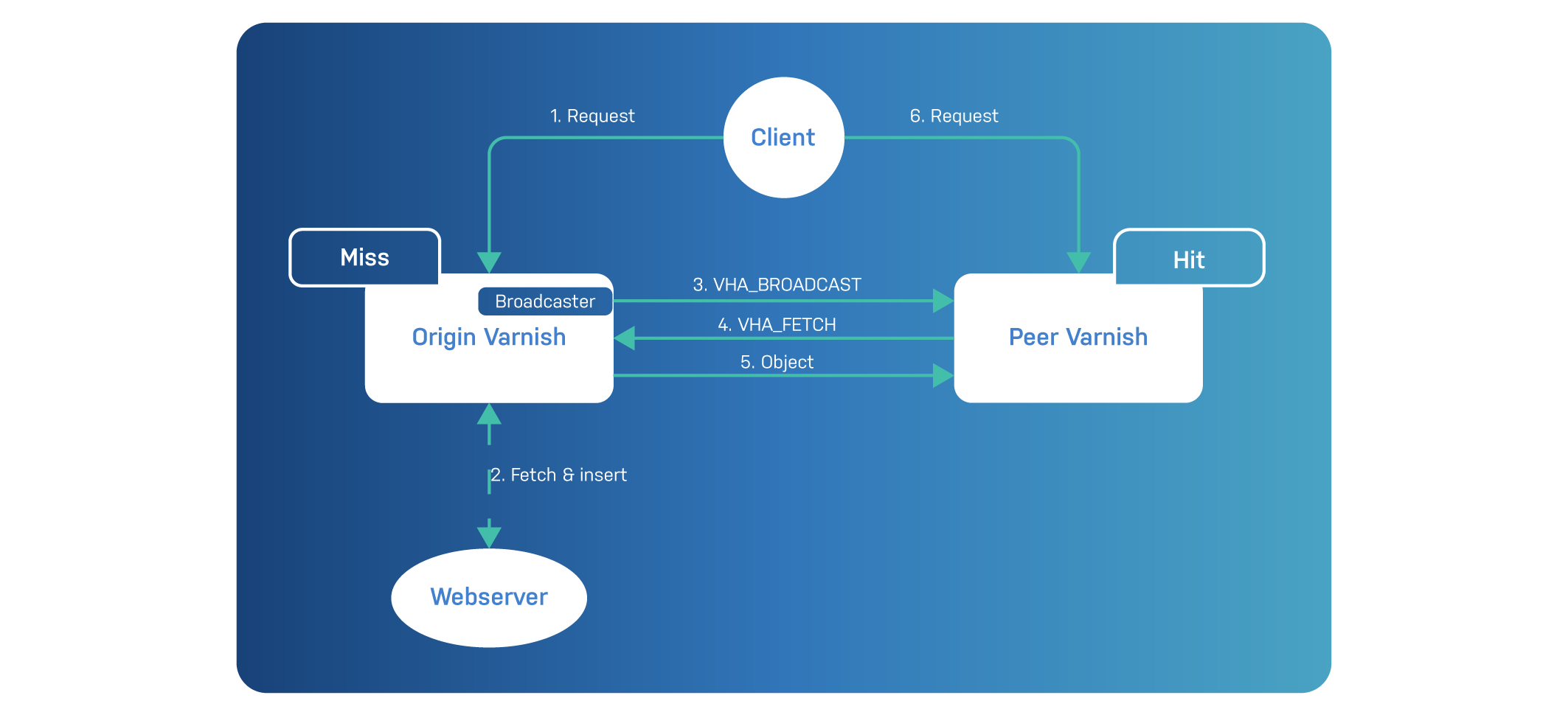
Let’s go through the different steps:
VHA_BROADCAST request to the other nodes in the cluster.VHA_BROADCAST request will send
a VHA_FETCH request to the VHA origin when they don’t have the
object in cache.Remember that this diagram only illustrates unidirectional replication. In reality, the VHA peer can become the VHA origin when it receives a request for an object it doesn’t have in cache. So in fact, replication can be bidirectional, or even omnidirectional.
The main thing to remember here is that VHA origin servers don’t push
the objects directly, but instead announce new cache insertions via a
VHA_BROADCAST request to all peers. This avoids broadcasting large
objects across the network, potentially resulting in network saturation.
Another thing to remember is that when peers attempt to fetch these new objects, they don’t get them from the backend web servers, but from the VHA origin server that announced it. This avoids unnecessary backend requests that may jeopardize stability, especially on a large VHA cluster.
Also important to know: the VHA peer will only acknowledge the
VHA_BROADCAST request and send a corresponding VHA_FETCH request if
it doesn’t have that object already in cache. This means that
replication only takes place for cache misses on the peers.
Efficiency also comes from the fact that VHA is designed for millisecond range replication. VHA already starts replicating as soon as the headers of the object are received. Even as data is streaming from the backend server to the VHA origin, the VHA peers start streaming the same content in parallel.
Not every cache miss will result in a VHA_BROADCAST request to the
VHA peers. The VHA logic will qualify which backend responses can be
replicated, based on a set of rules.
Here are some rules that exclude objects from being replicated:
bereq.uncacheable or beresp.uncacheable for the response
equal truemin_ttl
VHA setting. Three seconds by defaultmax_bytes VHA setting. 25
MB by defaultmax_requests_sec VHA setting. 200 by defaultThese rules make sense: if an object is short-lived or not cacheable at all, we really don’t want to spend time and resources replicating it to the other nodes in the cluster. It’s just not worth it.
The rules also ensure that replication doesn’t overload the network or the peer servers. It does this by limiting the size of replicated object and by rate limiting the number of in-flight replications.
The thresholds that are used to quantify some of these restrictions can be configured. We’ll talk about that soon.
It is important that the VHA_BROADCAST and VHA_FETCH requests are
secured. If the requests are tampered with, this can have a serious
impact on the integrity and consistency of the data but also the
stability of the platform.
The VHA_BROADCAST and VHA_FETCH requests are secured with a
time-based HMAC signature. This means that replication messages are
protected with a cryptographic signature that cannot be tampered with.
This ensures the integrity of the data.
Because the HMAC signature is time-based, it cannot be duplicated or replayed.
The VHA configuration requires a cluster-wide unique token. This
token is used as the signing key for the HMAC signature and is defined
by the token VHA setting.
The validity of the token can be configured via the token_ttl VHA
setting, which defaults to two minutes. This means that the HMAC
signature is valid for two minutes. After that, the request is no longer
considered valid.
These transactions can also be done over an HTTPS connection, ensuring that the outside world cannot decrypt the messages.
VHA is only available for Varnish Enterprise and is packaged as
varnish-plus-ha. Because it depends on the broadcaster, here’s how
you would install this on Debian or Ubuntu systems:
$ sudo apt-get install varnish-plus-ha varnish-broadcaster
This is the equivalent for RHEL, CentOS, and Fedora:
$ sudo yum install varnish-plus-ha varnish-broadcaster
The install will put the necessary VHA VCL files in the
/usr/share/varnish-plus/vcl/vha6 folder. It will also install the
custom vmod_vha VMOD.
The next step is to define your inventory inside nodes.conf. Here’s an
example from chapter 6 when we first introduced the broadcaster:
[eu]
eu-varnish1 = http://varnish1.eu.example.com
eu-varnish2 = http://varnish2.eu.example.com
eu-varnish3 = http://varnish3.eu.example.com
[us]
us-varnish1 = http://varnish1.us.example.com
us-varnish2 = http://varnish2.us.example.com
us-varnish3 = http://varnish3.us.example.com
Unless defined otherwise, replication will happen across these six nodes.
Make sure you restart the broadcaster after you have changed your inventory.
And finally, it’s a matter of including the necessary VCL and initializing VHA:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
call vha6_token_init;
}
And that’s all it takes. Enabling VHA from your VCL code is surprisingly simple.
We already referred to VHA settings earlier and that VCL example
shows how it is done using the vha6_opts.set() method. At the minimum
a token setting should be defined. All other settings are optional.
The vha6/vha_auto.vcl include is loaded from the vcl_path
directories. By default this is /etc/varnish and
/usr/share/varnish-plus/vcl. As mentioned before the VHA files are
located in /usr/share/varnish-plus/vcl/vha6.
The VHA files and the VMODs that are included are important and will hook in nicely with your existing VCL. It is a non-intrusive solution.
Although token is the only required setting, there are plenty of other
VHA settings that can be configured. We’ve grouped the settings per
topic.
Let’s have a look.
The broadcaster is a key component that initiates the replication. The
default broadcaster endpoint is http://localhost:8088.
This implies that the broadcaster is hosted locally. This is a common
pattern that makes using VHA quite simple. A potential downside is the
fact that you have to manage the nodes.conf inventory on all
broadcaster nodes. If for example, your inventory increases from a
five-node cluster to a six-node cluster, you’ll need to update the
nodes.conf inventory on all six broadcaster nodes.
If you want the broadcaster to be centralized, you can configure VHA
to send VHA_BROADCAST requests to a central endpoint.
Here’s a list of settings you can edit to change the endpoint:
broadcaster_scheme: the URL scheme to use. Defaults to http and
can be set to httpsbroadcaster_host: the hostname or IP address of the broadcaster.
Defaults to localhostbroadcaster_port: the TCP port on which the broadcaster is
available. Defaults to 8088Imagine that your broadcaster is available through
http://broadcaster.example.com. This would result in the following
VCL code:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("broadcaster_scheme", "http");
vha6_opts.set("broadcaster_host", "broadcaster.example.com");
vha6_opts.set("broadcaster_port", "80");
call vha6_token_init;
}
If we look back at our nodes.conf inventory, we have nodes in the EU
and the US. We might want to restrict replication within a
geographical region; otherwise we might experience latency because of
the distance between the nodes.
Again, imagine that this is our inventory:
[eu]
eu-varnish1 = http://varnish1.eu.example.com
eu-varnish2 = http://varnish2.eu.example.com
eu-varnish3 = http://varnish3.eu.example.com
[us]
us-varnish1 = http://varnish1.us.example.com
us-varnish2 = http://varnish2.us.example.com
us-varnish3 = http://varnish3.us.example.com
We can set the broadcaster_group setting to eu within the EU to
limit replication to only the EU nodes. Here’s the VCL to do that:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("broadcaster_group", "eu");
call vha6_token_init;
}
The VHA_BROADCAST request from the VHA origin to the VHA peer
contains a vha6-origin request header. This header contains the
endpoint that the peer should connect to when it sends out its
VHA_FETCH request.
The origin endpoint is automatically generated by VHA, but you can override it if required.
The autodetection of the origin scheme and origin port is based on
the port that is used for the incoming connection to the VHA origin.
The origin host is based on the VHA origin’s server.ip value.
The origin_scheme, origin, and origin_port settings can be used to
override these automatically generated values.
Here’s an example where we will force the peer to connect back to the VHA origin over HTTPS, even if original request was done over HTTP:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("origin_scheme", "https");
vha6_opts.set("origin_port", "443");
call vha6_token_init;
}
You can even redefine the host of the VHA origin. This allows you to potentially have peers request the new object from another system:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("origin", "vha-origin.example.com")
call vha6_token_init;
}
#### TLS
TLS is crucial these days, and all VHA components can be configured to use HTTPS endpoints.
The broadcaster_scheme VHA setting can be set to https to ensure
the communication between the VHA origin and the broadcaster is done
over TLS. If you do this, please make sure the broadcaster_port
setting also matches the broadcaster’s https-port value.
Here’s some VCL that shows you how a locally hosted broadcaster can be configured to use TLS:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("broadcaster_scheme", "https");
vha6_opts.set("broadcaster_port", "8443");
call vha6_token_init;
}
> Please keep in mind that your *broadcaster* instance has to be
> configured with *TLS* support to make this work.
The node definition in the broadcaster’s nodes.conf file can also
start with https://. This forces the broadcaster to send
VHA_BROADCAST requests to the peers over HTTPS and ensures that
the VHA_FETCH and the fetched responses are sent over HTTPS.
Even if your nodes.conf inventory has a http scheme, or no scheme at
all, it is still possible to enable TLS/SSL in VHA. It’s a matter of
setting origin_scheme to https and assigning the right port to
origin_port.
We already featured an example with both of these settings. Let’s make it a bit more interesting by making sure self-signed certificates can be used as well.
Here’s the code:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("origin_scheme", "https");
vha6_opts.set("origin_port", "443");
vha6_opts.set("origin_ssl_verify_peer", "false");
vha6_opts.set("origin_ssl_verify_host", "false");
call vha6_token_init;
}
By setting both origin_ssl_verify_peer and origin_ssl_verify_host to
false, the authenticity of a TLS/SSL certificate is ignored. That
allows using certificates that were not issued by a certificate
authority. In this case, the certificates were self-signed.
Disabling the TLS/SSL verification process can also be done for the broadcaster. However, the broadcaster plays two roles and that has an impact on the configuration.
To the VHA origin, the broadcaster acts as a server. To use
self-signed certificates, you need to set broadcaster_ssl_verify_peer
and broadcaster_ssl_verify_host to false. This ensures that VHA
doesn’t complain when the certificate is not authentic.
But the broadcaster also acts as the client towards the VHA peers.
When https schemes are used in the nodes.conf, those endpoints need
to have valid certificates as well, regardless of the VHA settings.
To make sure peer and host verification within the broadcaster is
also disabled, you have to set the broadcaster’s tls-verify runtime
configuration parameter to NONE.
As discussed earlier, VHA has put some limitations in place that impact how and when replication takes place.
The min_ttl setting, for example, defines what the minimum TTL of an
inserted object must be before it is considered for replication. The
default value is 3s.
The max_bytes setting defines the upper limit in terms of payload
size. By default this value is 25000000. This means that for HTTP
responses with a Content-Length header that exceeds 25000000 bytes,
the object will not be replicated.
The max_requests_sec defines the maximum number of in-flight
transactions per second that are tolerated before replication is
halted. The default value is 200.
The fetch_timeout setting will limit the amount of time the VHA peer
can spend waiting for the first byte of the object to be returned from
the VHA origin. By default this is unlimited.
So let’s throw these settings together into a single VCL example:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("min_ttl", "10s");
vha6_opts.set("max_bytes", "100000000");
vha6_opts.set("max_requests_sec", "1000");
vha6_opts.set("fetch_timeout", "60s");
call vha6_token_init;
}
These settings will prevent objects from being replicated if their TTL is lower than ten seconds, if the payload of the HTTP response is larger than 100 MB, or if there are more than 1000 requests per second in-flight.
When replication is active, the VHA_FETCH call is allowed to wait one
minute before the first byte comes in. Otherwise the replication call
fails.
In the previous subsection, we talked about limits and when replication
is prevented. But these are global settings. However, the skip setting
allows you to skip replication on a per-request basis.
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
call vha6_token_init;
}
sub vcl_backend_fetch {
if(bereq.url ~ "^/video") {
vha6_request.set("skip", "true");
}
}
The example above will skip replication if the backend request URL
matches the ^/video regular expression pattern. Skipping replication
on a per-request basis can only be done inside vcl_backend_fetch and
vcl_backend_response.
It is possible in VHA to force a transaction to update an existing object in cache. So even if the VHA peers have the object in cache, and would otherwise ignore the replication request, a new cache insertion can be forced.
The example below features a news website where all URLs that start with
/breaking-news are forcefully replicated:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
call vha6_token_init;
}
sub vcl_backend_fetch {
if(bereq.url ~ "^/breaking-news") {
vha6_request.set("force_update", "true");
}
}
### Monitoring
VHA heavily relies on vmod_kvstore for managing options and storing
metrics. With varnishstat these metrics can be visualized.
Here’s an example of some VHA6 stats using varnishstat:
$ varnishstat -f *vha6_stats* -1
KVSTORE.vha6_stats.boot.broadcast_candidates 8 0.02 Broadcast candidates
KVSTORE.vha6_stats.boot.broadcasts 7 0.02 Successful broadcasts
KVSTORE.vha6_stats.boot.fetch_peer 2 0.01 Broadcasts which hit this peer node (fetches)
KVSTORE.vha6_stats.boot.fetch_origin 7 0.02 Fetches which hit this origin node
KVSTORE.vha6_stats.boot.fetch_origin_deliver 7 0.02 Fetches which were delivered from origin to the peer
KVSTORE.vha6_stats.boot.fetch_peer_insert 2 0.01 Fetches which were successfully inserted
KVSTORE.vha6_stats.boot.error_fetch 0 0.00 Fetches which encountered a network error
KVSTORE.vha6_stats.boot.error_fetch_insert 0 0.00 Fetches which encountered an origin error
KVSTORE.vha6_stats.boot.broadcast_skip 1 0.00 Broadcast candidate has a VCL override
Here’s what we know, based on the output above:
The
-1varnishstat flag sends the counters to the standard output, instead of presenting the statistics as a continuously updated list.
The varnishlog program will also contain detailed logging information
on VHA transactions.
The following varnishlog command will display logs for all
transactions of which the request method starts with VHA. This
includes VHA_BROADCAST requests on VHA origin servers and
VHA_FETCH requests on peer servers:
$ varnishlog -g request -q "ReqMethod ~ VHA"
This command should be run on all nodes in your cluster, as it is
unclear at what point a node is a VHA origin or a VHA peer. The
output is extremely verbose. Let’s just look at the VHA_BROADCAST
request information:
- ReqMethod VHA_BROADCAST
- ReqURL /fed4a6511f33937f6de966469f98ad6f6ca1f9f4a2a41a24ef5d1abdde09980d
- ReqProtocol HTTP/1.1
- ReqHeader Host: example.com
- ReqHeader Vha6-Date: Fri, 20 Nov 2020 13:38:12 GMT
- ReqHeader Vha6-Origin: https://192.168.0.5:443
- ReqHeader Vha6-Origin-Id: varnish1
- ReqHeader Vha6-Token: c5391fd44cba8ede76f4bd9b02d6c135e217608d63e5c07f3979ac854918162e
- ReqHeader Vha6-Url: /contact
- ReqHeader vha6-method: VHA_BROADCAST
- ReqHeader vha6-peer-id: varnish2
As you can see, the URL of the replicated object is
https://example.com/contact. The varnish1 server acted as the origin
and can be reached through https://192.168.0.5:443. This information
was received by the varnish2 server, which acted as the peer for
this transaction.
Similar information can be extracted for the VHA_FETCH call:
- ReqMethod VHA_FETCH
- ReqURL /fed4a6511f33937f6de966469f98ad6f6ca1f9f4a2a41a24ef5d1abdde09980d
- ReqProtocol HTTP/1.1
- ReqHeader Host: example.com
- ReqHeader Vha6-Date: Fri, 20 Nov 2020 13:38:12 GMT
- ReqHeader Vha6-Origin: https://192.168.0.5:443
- ReqHeader Vha6-Origin-Id: varnish1
- ReqHeader Vha6-Token: c5391fd44cba8ede76f4bd9b02d6c135e217608d63e5c07f3979ac854918162e
- ReqHeader Vha6-Url: /contact
- ReqHeader vha6-method: VHA_FETCH
- ReqHeader vha6-peer-id: varnish2
This request was processed by varnish1, which is the VHA origin for
this transaction. The information is very similar to the VHA_BROADCAST
request and is an acknowledgement by VHA peer.
When the VHA origin responds to the VHA peer for the VHA_FETCH
request, the following response information can be found in the VSL
logs of the VHA origin:
- RespProtocol HTTP/1.1
- RespStatus 200
- RespReason OK
- RespHeader Date: Fri, 20 Nov 2020 13:38:12 GMT
- RespHeader Content-Type: text/html
- RespHeader Content-Length: 612
- RespHeader Last-Modified: Tue, 27 Oct 2020 15:09:20 GMT
- RespHeader ETag: "5f983820-264"
- RespHeader X-Varnish: 23 65558
- RespHeader Age: 0
- RespHeader Via: 1.1 varnish (Varnish/6.0)
- RespHeader vha6-stevedore-ttl: 120.000s
- RespHeader vha6-stevedore-ttl-rt: 119.973s
- RespHeader vha6-stevedore-grace: 10.000s
- RespHeader vha6-stevedore-keep: 0.000s
- RespHeader vha6-stevedore-uncacheable: false
- RespHeader vha6-stevedore-storage: storage.s0
- RespHeader vha6-stevedore-age: 0
- RespHeader vha6-stevedore-insert: Fri, 20 Nov 2020 13:38:12 GMT
- RespHeader vha6-origin: varnish1
- RespHeader vha6-seal: b49ad1fcc95f1a740cddf65c8c9d653bd0c3737baa8bc684442d8988dc64fea6
This looks like a regular HTTP response, but it also includes some
metadata in the form of vha6-stevedore-* headers.
It is technically possible to set up VHA without the broadcaster.
Although the broadcaster is essential for a multi-node cluster, it is not a hard requirement for a two-node cluster.
You can also send a VHA_BROADCAST request directly to your second
node, as illustrated below:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("broadcaster_host", "varnish2.example.com");
vha6_opts.set("broadcaster_port", "443");
vha6_opts.set("broadcaster_scheme", "https");
call vha6_token_init;
}
We actually set the broadcaster_host to the host of your other
Varnish node instead of relying on the broadcaster for this.
The same thing happens on your second node: setting the
broadcaster_host to your first Varnish node. By doing this, you have
bidirectional replication.
Here’s the configuration for your second node:
vcl 4.1;
include "vha6/vha_auto.vcl";
sub vcl_init {
vha6_opts.set("token", "secret123");
vha6_opts.set("broadcaster_host", "varnish1.example.com");
vha6_opts.set("broadcaster_port", "443");
vha6_opts.set("broadcaster_scheme", "https");
call vha6_token_init;
}
Although this solution is viable and can be considered a high-availability solution, it does take away a lot of flexibility. Unless you’re certain that your two-node setup will remain a two-node setup, using the broadcaster is the recommended way to go.
There is also an important operational question that hasn’t been answered or raised:
How do you add or remove nodes from the cluster?
Failing nodes are supposed to be removed from the broadcaster’s
inventory. This also applies to nodes that are removed when scaling in.
And when a spike in demand is expected, extra nodes should be registered
in the node.conf file.
Whenever an inventory change takes place, the nodes.conf file needs to
be reprovisioned, and the broadcaster needs to be reloaded. By sending
a SIGHUP signal to the broadcaster, the nodes.conf file is read,
and the configuration reloaded.
Here’s how the broadcaster process reports this:
DEBUG: Sighup notification received, reloading configuration
DEBUG: Reading configuration from /etc/varnish/nodes.conf
DEBUG: Done reloading configuration
You can do this manually by triggering a script to reprovision the
inventory and reloading the broadcaster. But unless you have a proper
discovery tool, you will not know when to change your nodes.conf file
and what servers are to be considered.
Especially on environments with a dynamic inventory, like the cloud, this can become a serious challenge.
Luckily, Varnish Enterprise comes with the varnish-discovery program
that dynamically provisions your broadcaster’s nodes.conf, and
reloads the broadcaster service.
Varnish Discovery supports a couple of data providers that are used to
provision the nodes.conf file.
These are the providers that are currently supported:
With the exception of DNS, API calls are made to the data provider to retrieve inventory information.
For cloud platforms like AWS or Azure, the nodes that are associated with a specific autoscaling group are retrieved. For Kubernetes these are pods that are associated with an endpoint list.
The node information that was collected from the data provider is then
flushed to the nodes.conf file and a SIGHUP signal is sent to the
broadcaster process.
The varnish-discovery program will emit the following output when a
change is detected:
Generating new nodefile /etc/varnish/nodes.conf (2020-11-23 16:14:17.4384255 +0000 UTC m=+58.052877601)
Varnish Discovery is only available for Varnish Enterprise and is
packaged as varnish-plus-discovery. Because this service also depends
on the broadcaster, here’s how you would install this on Debian or
Ubuntu systems:
$ sudo apt-get install varnish-plus-discovery varnish-broadcaster
This is the equivalent for RHEL, CentOS, and Fedora:
$ sudo yum install varnish-plus-discovery varnish-broadcaster
A systemd service file is available in
/lib/systemd/system/varnish-discovery.service. This is the default
service definition of that file:
[Unit]
Description=Varnish Discovery
#After=network-online.target
#Requisite=network-online.target
[Service]
ExecStart=/usr/bin/varnish-discovery dns \
--group example.com \
--nodefile /etc/varnish/nodes.conf \
--warnpid /run/vha-agent/vha-agent.pid
[Install]
WantedBy=multi-user.target
The standard configuration will most likely not work for you. But once the right runtime parameters are set, you can run the following commands to enable and start the service:
$ sudo systemctl enable varnish-discovery
$ sudo systemctl start varnish-discovery
Configuring varnish-discovery is done by setting the right runtime
parameters. Let’s take the default settings from the systemd service
file and explain what they mean:
The first argument is the name of the provider to use. By default this
is dns, but you can set this to aws, azure, or kubernetes.
The --group parameter is used to query the group that contains the
nodes we want in our inventory. The meaning of group varies on the
provider that is used:
dns, the --group parameter refers to the DNS record that
contains the IP addresses of the Varnish nodes.aws, the --group parameter refers to the autoscaling group
that contains the EC2 instances on which Varnish is hosted.azure, the --group parameter refers to the virtual machine
scale set that contains the virtual machines on which Varnish is
hosted.k8s, the --group parameter refers to the endpoint that
contains the Varnish pods.The --nodefile parameter refers to the location of the nodes.conf
file. This is where varnish-discovery sends its output.
The --warnpid parameter is the PID file that needs to be signaled
when changes to the nodes.conf file have occurred. By default this is
/run/vha-agent/vha-agent.pid, but this should be the PID file of the
broadcaster service.
Please keep in mind that you probably have to add the --pid runtime
parameter to the systemd configuration of your broadcaster. This
ensures that the PID file is written out to the desired location.
There are some other parameters you can configure as well. Here’s a quick overview:
--proto is the backup protocol that will be used in nodes.conf in
case a protocol wasn’t returned from the data provider. Defaults to
http--port is the backup port that is used when the port wasn’t returned
by the data provider. If omitted, the port is inferred from the
protocol.--ipv4 and --ipv6 allow you to filter nodes on their IP protocol
version. If omitted, both IPv4 and IPv6 addresses are allowed for
nodes.--once will not continuously query the data provider, but instead
will only query it once.--every is used to define the frequency with which the data provider
is queried. Defaults to two secondsHere’s an example where we use some more runtime parameters:
/usr/bin/varnish-discovery dns \
--group example.com \
--nodefile /etc/varnish/nodes.conf \
--warnpid /var/run/broadcaster.pid \
--proto https \
--port 444 \
--ipv4 --every 10
This example will resolve the example.com hostname every ten seconds
and will only retrieve IPv4 addresses. The nodes that are written to
/etc/varnish/nodes.conf will be prefixed with https:// and suffixed
with :444 for the port.
Once the nodes.conf file is written to disk, the PID inside
/var/run/broadcaster.pid is used to send a SIGHUP signal to the
broadcaster.
The dns provider will resolve a hostname that was provided by the
--group parameter. The IP addresses resolved from the DNS call will
end up in the nodes.conf file.
If an IP address matches the local machine, the local hostname is used
instead of the IP address. You can disable this behavior by adding the
--no-hostname runtime parameter.
This is a pretty basic solution that works on any platform. However, it is important to make sure the TTL of your DNS records is not too high. Otherwise local DNS resolvers might cache the value for longer than expected.
The Amazon Web Services (AWS) provider interacts with the AWS API.
The --group parameter refers to the autoscaling group that is
expected to be defined in your AWS environment.
The API call will retrieve the private DNS name and the private IP
address for every node that is part of the autoscaling group. This
information is then written to the nodes.conf.
The -region parameter sets the AWS region where the autoscaling
group is defined. This is only necessary when the default region is not
configured on your system via the aws configure command.
The aws program is a CLI interface for the AWS API. The
aws configure command will assist with configuring the necessary
environment variables for authenticating with the AWS API.
You can also define the following environment variables for authentication:
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEYAWS_DEFAULT_REGIONOr you can define an AWS_SHARED_CREDENTIALS_FILE environment variable
that refers to a shared credentials file.
Once the proper environment variables are set up, VHA will dynamically replicate its objects to Varnish servers that are part of this autoscaling group.
Azure is Microsoft’s cloud platform, and the azure provider within
varnish-discovery is very similar to the aws one. The --group
parameter refers to a virtual machine scale set (VMSS), which is
Azure’s version of an autoscaling group.
There are two custom parameters for Azure you can configure:
-resourcegroup-subscriptionidThe resource group and subscription of the VMSS can be configured.
This is just the fallback value in case these weren’t configured via
az configure.
The az program is also a CLI interface. It interacts with the Azure
API and sets some environment variables that are used for
authentication.
Here’s the list of environment variables that are used for authentication:
AZURE_SUBSCRIPTION_IDAZURE_TENANT_IDAZURE_CLIENT_IDAZURE_CLIENT_SECRETAZURE_LOCATION_DEFAULTAZURE_BASE_GROUP_NAMEBy using az configure, these environment variables will be set for
you, and the VMSS information is picked up.
If you’re using Azure, this is an excellent way to dynamically scale your Varnish setup and make sure VHA keeps working.
Kubernetes is a framework for automating the deployments, scaling, and management of containerized applications. It mostly uses Docker containers.
When Varnish Enterprise is run inside containers on a Kubernetes
cluster, the k8s is there to figure out the various endpoints of a
service. The --group parameter refers to a service inside a
Kubernetes cluster. The service is the entrypoint to a set of pods,
which contains the actual containers.
The service maps the endpoints of each pod, and our k8s provider
will fetch those endpoints and provision them in nodes.conf.
Authentication with the API of that cluster is done based on a set of parameters:
--server: the URL of the API. Defaults to https://kubernetes--token: the path to the token file. Defaults to
/var/run/secrets/kubernetes.io/serviceaccount/token--cacert: the path to the CA certificate file. Defaults to
/var/run/secrets/kubernetes.io/serviceaccount/ca.crt--namespace: the path to the namespace file. Defaults to
/var/run/secrets/kubernetes.io/serviceaccount/namespaceThese parameters are entirely optional, and the default values work
perfectly fine if varnish-discovery runs inside a Kubernetes pod.
The /var/run/secrets/kubernetes.io/serviceaccount/ path is accessible
within the pod and the corresponding files are located in there.
However, if varnish-discovery runs elsewhere, the Kubernetes API
needs to be called externally, which might require the authentication
parameters to be tuned.
Here’s an example where custom parameters are used for Kubernetes authentication:
/usr/bin/varnish-discovery k8s \
--group my-varnish-service \
--nodefile /etc/varnish/nodes.conf \
--warnpid /var/run/broadcaster.pid \
--server https://kubernetes-api.example.com \
--token /path/to/token \
--cacert /path/to/ca.crt \
--namespace /path/to/namespace
Behind the scenes https://kubernetes-api.example.com is set as the
base URL, and the content of /path/to/namespace is used to determine
the URL. If /path/to/namespace contains my-namespace, the URL will
become the following:
https://kubernetes-api.example.com/api/v1/namespaces/my-namespace/endpoints
Authentication is required to access this API call. This is done via a
bearer authentication token. The value of this token is the content of
the file that was referred to via the --token parameter. In our case
this is /path/to/token.
The TLS certificates that are used to encrypt the HTTPS connection are self-signed. In order to correctly validate the server certificate, a custom CA certificate is passed. This is the certificate that was used to sign the server certificates.
If you were to try this yourself using curl, this would be the
corresponding call:
$ curl -H "Authorization: Bearer $(head -n1 /path/to/token)" \
--cacert /path/to/ca.crt \
https://kubernetes-api.example.com/api/v1/namespaces/$(head -n1 /path/to/namespace)/endpoints
And that’s exactly what the k8s provider does behind the scenes.