When a Varnish server is tasked with proxying backend requests to multiple origin servers, it is important that the right backend is selected.
If there is an affinity between the client and a specific backend, or the request and a specific backend, VCL offers you the flexibility to define rules and add the required logic on which these backend routing decisions are based.
VCL has the req.backend_hint and the bereq.backend variables that
can be set to assign a backend. This allows you to make backend routing
decisions based on HTTP request or client information.
There are also situations where you don’t want to select one backend, but you want all backends from the pool to participate. The goal is to distribute requests across those backends for scalability reasons. We call this load balancing.
Varnish has a VMOD called vmod_directors, which takes care of load
balancing. This VMOD can register backends, and based on a
distribution algorithm, a backend is selected on a per-request basis.
Even though load balancing aims to evenly distribute the load across all servers in the pool, some directors allow you to configure a level of affinity with one or more backends.
The directors VMOD is an in-tree VMOD that is shipped with Varnish by default. It has a relatively consistent API for initialization and for adding backends.
A director object will pick a backend when the .backend() method is
called. The selected backend can be assigned to Varnish using
req.backend_hint and bereq.backend.
The round-robin director will create a director object that will
cycle through backends every time .backend() is selected.
Here’s a basic round-robin example with three backends:
vcl 4.1;
import directors;
backend backend1 {
.host = "backend1.example.com";
.port = "80";
}
backend backend2 {
.host = "backend2.example.com";
.port = "80";
}
backend backend3 {
.host = "backend3.example.com";
.port = "80";
}
sub vcl_init {
new vdir = directors.round_robin();
vdir.add_backend(backend1);
vdir.add_backend(backend2);
vdir.add_backend(backend3);
}
sub vcl_recv {
set req.backend_hint = vdir.backend();
}
new vdir = directors.round_robin() will initialize the round-robin
director object. The vdir.add_backend() method will add the three
backends to the director.
And every time vdir.backend() is called, the director will cycle
through those backends.
Because it is done in a round-robin fashion, the order of execution is very predictable.
The output below comes from the varnishlog binary that filters on the
BackendOpen tag that indicates which backend is used:
$ varnishlog -g raw -i BackendOpen
32786 BackendOpen b 26 boot.backend1 172.21.0.2 80 172.21.0.5 56422
24 BackendOpen b 27 boot.backend2 172.21.0.4 80 172.21.0.5 45792
32789 BackendOpen b 28 boot.backend3 172.21.0.3 80 172.21.0.5 54702
27 BackendOpen b 26 boot.backend1 172.21.0.2 80 172.21.0.5 56422
32792 BackendOpen b 27 boot.backend2 172.21.0.4 80 172.21.0.5 45792
32795 BackendOpen b 28 boot.backend3 172.21.0.3 80 172.21.0.5 54702
As you can see backend1 is used first, then backend2, and finally
backend3. This order of execution is respected for subsequent
requests.
Round-robin will ensure an equal distribution of load across all origin servers.
The random director will distribute the load using a weighted random probability distribution.
The API doesn’t differ much from the round-robin director. In the snippet below, there is equal weighting:
sub vcl_init {
new vdir = directors.random();
vdir.add_backend(backend1, 1);
vdir.add_backend(backend2, 1);
vdir.add_backend(backend3, 1);
}
The formula that is used to determine the weighting is
100 * (weight / .(sum(all_added_weights))).
Here’s another VCL snippet with unequal weighting:
sub vcl_init {
new vdir = directors.random();
vdir.add_backend(backend1, 1);
vdir.add_backend(backend2, 2);
vdir.add_backend(backend3, 3);
}
If we apply the formula for this example, the distribution is as follows:
backend1 has a 16.66% probability of being selected.backend2 has a 33.33% probability of being selectedbackend3 has a 50% probability of being selected.These weights are useful when some of the backends shouldn’t receive the same amount of traffic. This may be because they don’t have the same dimensions and are less powerful.
Watch out: setting the weight of a backend to zero gives the backend a zero percent probability of being selected.
Another kind of load balancing we can use in Varnish is only based on potential failure.
A fallback director will try each of the added backends in turn and return the first one that is healthy.
Configuring this type of director is very similar to the round-robin
one. Here’s the vcl_init snippet:
sub vcl_init {
new vdir = directors.fallback();
vdir.add_backend(backend1, 1);
vdir.add_backend(backend2, 1);
vdir.add_backend(backend3, 1);
}
backend1 is the main backend, and will always be used if it is
healthy.backend1 fails, backend2 becomes the selected backend.backend1 and backend2 fail, backend3 is used.If a higher-priority backend becomes healthy again, it will become the main backend.
By setting the sticky argument to true, the fallback director will
stick with the selected backend, even if a higher-priority backend
becomes available again.
Here’s how you enable stickiness:
sub vcl_init {
new vdir = directors.fallback(true);
vdir.add_backend(backend1, 1);
vdir.add_backend(backend2, 1);
vdir.add_backend(backend3, 1);
}
The hash director is used to consistently send requests to the same backend, based on a hash that is computed by the director and that is associated with a backend.
The example below contains a very common use case: sticky IP. This means that requests from a client are always sent to the same backend.
vcl 4.1;
import directors;
backend backend1 {
.host = "backend1.example.com";
.port = "80";
}
backend backend2 {
.host = "backend2.example.com";
.port = "80";
}
backend backend3 {
.host = "backend3.example.com";
.port = "80";
}
sub vcl_init {
new vdir = directors.hash();
vdir.add_backend(backend1, 1);
vdir.add_backend(backend2, 1);
vdir.add_backend(backend3, 1);
}
sub vcl_recv {
set req.backend_hint = vdir.backend(client.ip);
}
If you want to horizontally scale your cache, you can use the hash director to send all requests for the same URL to the same Varnish server. To achieve this, you need two layers of Varnish:
The following diagram illustrates this:
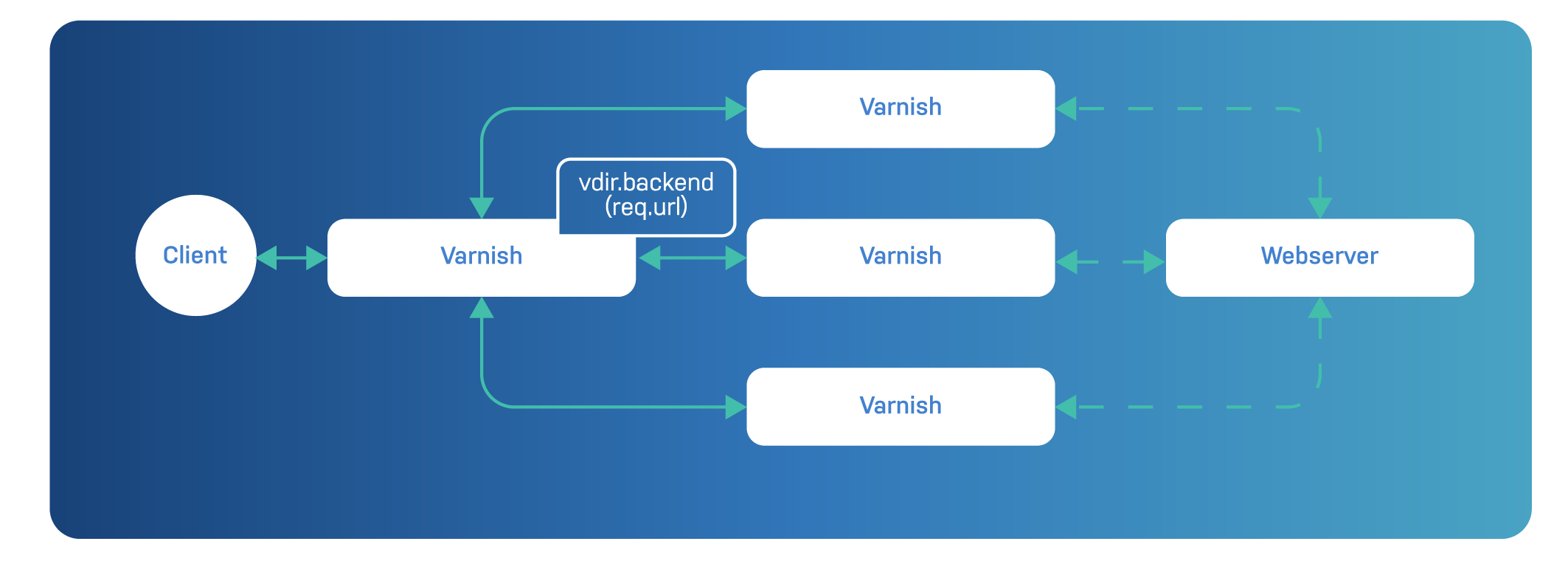
The top-level Varnish server, which acts as a router, can use the following VCL code to evenly distribute the content across to lower-level Varnish servers:
vcl 4.1;
import directors;
backend varnish1 {
.host = "varnish1.example.com";
.port = "80";
}
backend varnish2 {
.host = "varnish2.example.com";
.port = "80";
}
backend varnish3 {
.host = "varnish3.example.com";
.port = "80";
}
sub vcl_init {
new vdir = directors.hash();
vdir.add_backend(varnish1, 1);
vdir.add_backend(varnish2, 1);
vdir.add_backend(varnish3, 1);
}
sub vcl_recv {
set req.backend_hint = vdir.backend(req.url);
}
By scaling horizontally, you can cache a lot more data than on a single server. The hash director ensures there is not content duplication on the lower-level nodes. And if required, the top-level Varnish server can also cache some of the hot content.
Whereas the previous example was quite vertical, the next one has the same capabilities but structured horizontally.
Imagine the setup featured in this diagram:
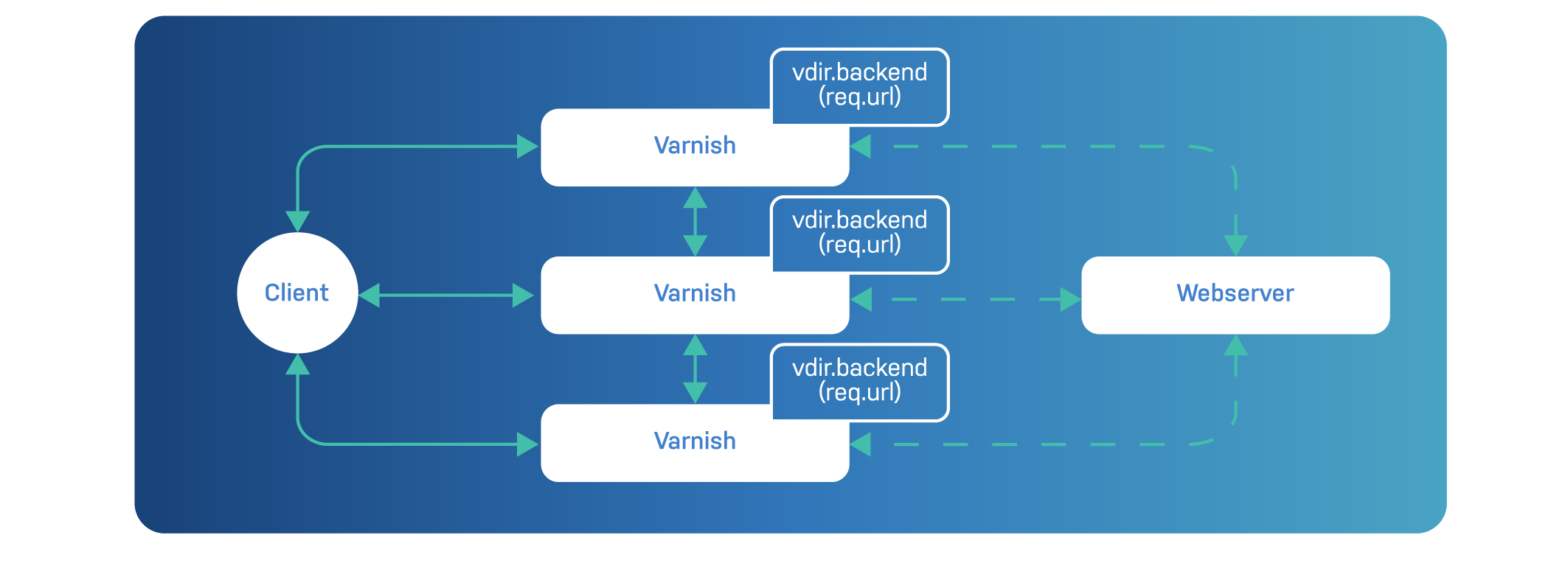
What you have is three Varnish servers that are aware of each other.
The vdir.backend(req.url) method creates a hash and selects a node.
When Varnish notices that the selected node has the same IP address as it has, it routes the request to the origin server. If the IP address is not the same, the request is routed to another Varnish node.
What is also interesting to note is that all Varnish servers create the same hash, so the outcome is predictable.
Here’s the VCL code:
vcl 4.1;
import directors;
backend varnish1 {
.host = "varnish1.example.com";
.port = "80";
}
backend varnish2 {
.host = "varnish2.example.com";
.port = "80";
}
backend varnish3 {
.host = "varnish3.example.com";
.port = "80";
}
backend origin {
.host = "origin.example.com";
.port = "80";
}
sub vcl_init {
new vdir = directors.hash();
vdir.add_backend(varnish1, 1);
vdir.add_backend(varnish2, 1);
vdir.add_backend(varnish3, 1);
}
sub vcl_recv {
set req.backend_hint = vdir.backend(req.url);
set req.http.x-shard = req.backend_hint;
if (req.http.x-shard == server.identity) {
set req.backend_hint = origin;
} else {
return(pass);
}
}
The hash director is a relatively simple and powerful implementation, but when nodes are added or temporarily removed, a lot of keys have to be remapped.
Although there is a level consistency, the hash director doesn’t apply a true consistent hashing algorithm.
When a backend that is part of your hash director is taken out of commission, not only the hashes that belonged to that server have to be remapped to the remaining nodes, a lot of other hashes from healthy servers do as well.
This is more or less done by design, as the main priority of the hash director is fairness: keys have to be equally distributed across the backend servers to avoid overloading a single backend.
The shard director behaves very similarly to the hash director: a hash is composed from a specific key, and this hash is consistently mapped to a backend server.
However, the shard director has a lot more options it can configure. It also applies a real consistent hashing algorithm with replicas, which we’ll talk about in a minute.
Its main advantage is that when the backend configuration or health state changes, the association of keys to backends remains as stable as possible.
In addition, the ramp-up and warmup features can help to further improve user-perceived response times.
Here’s an initial VCL example where the request hash from vcl_hash
is used as the key. This hash is consistently mapped to one of the
backend servers:
vcl 4.1;
import directors;
backend backend1 {
.host = "backend1.example.com";
.port = "80";
}
backend backend2 {
.host = "backend2.example.com";
.port = "80";
}
backend backend3 {
.host = "backend3.example.com";
.port = "80";
}
sub vcl_init {
new vdir = directors.shard();
vdir.add_backend(backend1);
vdir.add_backend(backend2);
vdir.add_backend(backend3);
vdir.reconfigure();
}
sub vcl_backend_fetch {
set bereq.backend = vdir.backend();
}
The shard director can also pick an arbitrary key to hash. Although
the .backend() method doesn’t need any input parameters, it does
default to HASH. As explained earlier, this is the request hash from
vcl_hash.
You can also hash in the URL, which differs from the complete hash because the hostname and any custom variations will be missing.
Here’s how you configure URL hashing:
sub vcl_backend_fetch {
set bereq.backend = vdir.backend(URL);
}
Just like the hash director, you can hash an arbitrary key. If we want to create sticky sessions and use the client IP address to consistently route clients to the same backend, we can use the following snippet:
sub vcl_backend_fetch {
set bereq.backend = vdir.backend(KEY,vdir.key(client.ip));
}
The shard director has a warmup and a ramp-up feature. Both are related to gradually introducing traffic to a backend, though warmup is about gradually sending requests to other backends, and ramp-up is about gradually reintroducing the main backend.
The first snippet will set the default warmup probability to 0.5:
vdir.set_warmup(0.5)
This method will set the warmup on all backends and ensures that around 50% of all requests will be sent to an alternate backend. This is done to warm up that node in case it gets selected.
Warmup only works on healthy nodes, can only happen if a node is not in
ramp-up, and if the alternate backend selection didn’t explicitly
happen in the .backend() method.
Here’s an example where the warmup value is set upon backend selection:
sub vcl_backend_fetch {
set bereq.backend = vdir.backend(by=URL, warmup=0.1);
}
In this case the warmup value will send about 10% of traffic to the alternate backend, and it also uses the URL for hashing.
Warming up an alternate backend doesn’t seem that useful when you talk about regular web servers, but if you look at it from a two-layer Varnish setup, it definitely make sense.
Here’s an illustration where warmup is used to make sure second-tier Varnish servers are warmed up in case other nodes fail:
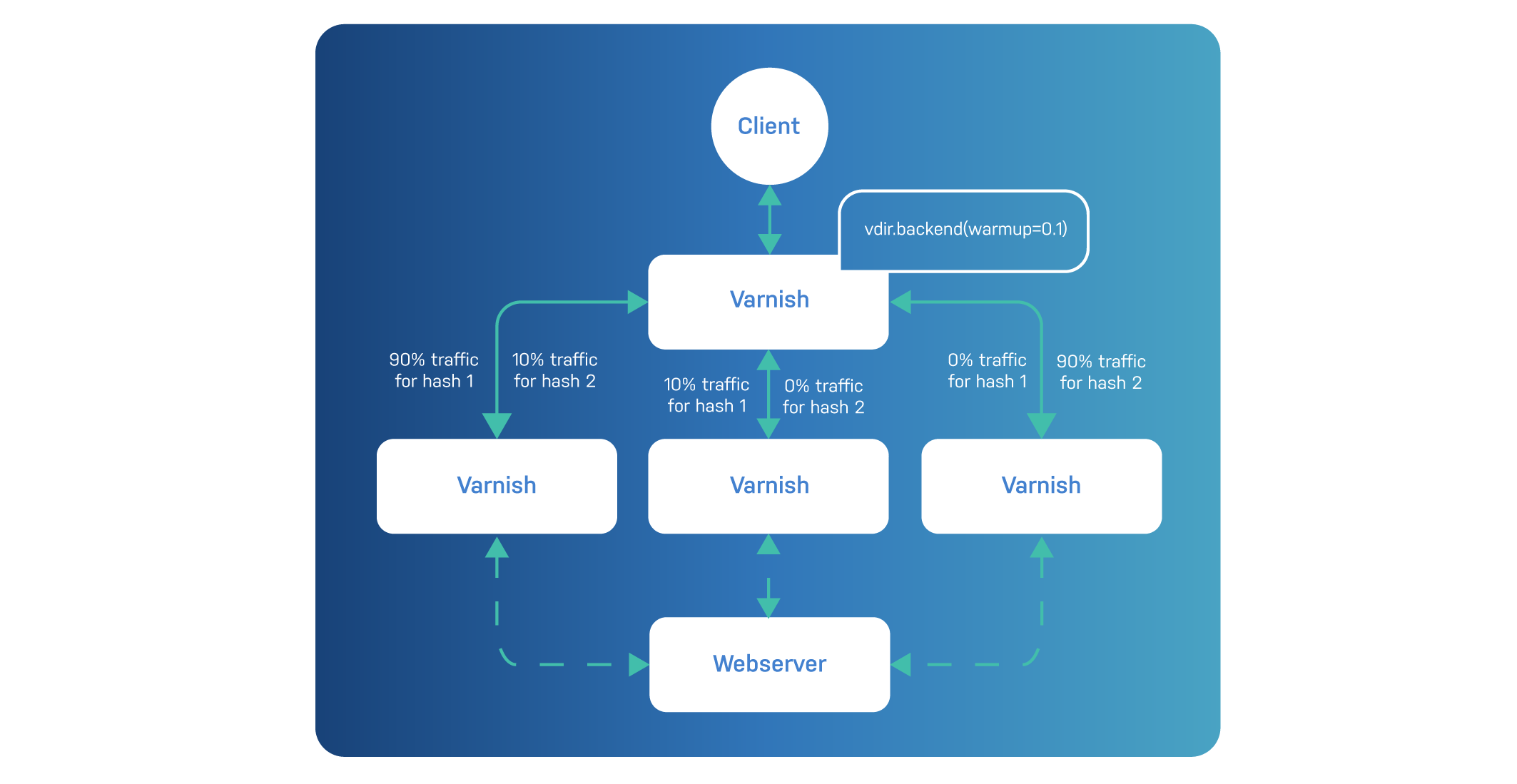
Whereas warmup happens on healthy servers, ramp-up happens on servers that have recently become healthy, either because they are new or because they recovered from an outage.
Ramp-up can be set globally, or on a per-backend basis. Here’s a VCL snippet that sets the global ramp-up to a minute:
vdir.set_rampup(1m);
When a backend becomes healthy again, the relative weight of the backend is pushed all the way down, and gradually increases for the duration of the ramp-up period.
While a backend is ramping up, it receives a fraction of its normal traffic, while the next alternative backend takes the rest. Eventually this smooths out, and after a while the backend can be considered fully operational.
Ramp-up can only happen when the alternative backend server was not
explicitly set in the .backend() method.
Here’s a snippet where the ramp-up period differs per backend:
sub vcl_init {
new vdir = directors.shard();
vdir.add_backend(backend1, rampup=5m);
vdir.add_backend(backend2, rampup=30s);
vdir.add_backend(backend3);
vdir.reconfigure();
}
In this case, backend1 has a five-minute rampup period, whereas
backend2 has a ten-second rampup period. backend3, however, takes
its rampup duration from the global setting.
When .backend() is executed and a backend is selected, rampup is
enabled by default unless rampup durations are set to 0s.
It is possible to still disable rampup on a per-backend request basis:
sub vcl_backend_fetch {
set bereq.backend = vdir.backend(rampup=false);
}
What makes the shard director so interesting is the fact that it uses consistent hashing with replica support.
Imagine the shard director as ring where each backend covers parts of the ring. Not every backend gets an equal amount of space. This is decided somewhat randomly.
Hashes are assigned to specific backends and because equidistribution is not a priority, some backends may receive a disproportionate number of requests.
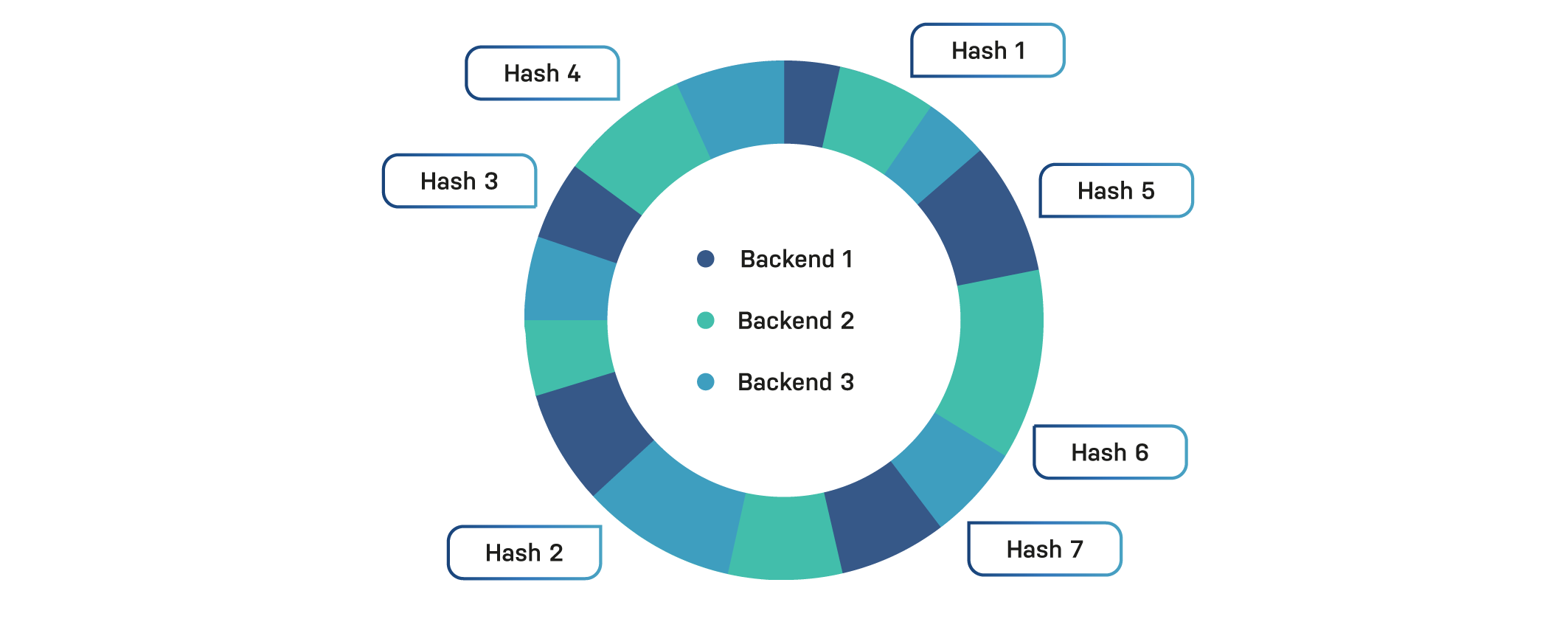
Here’s a simplistic pie chart that illustrates this concept:
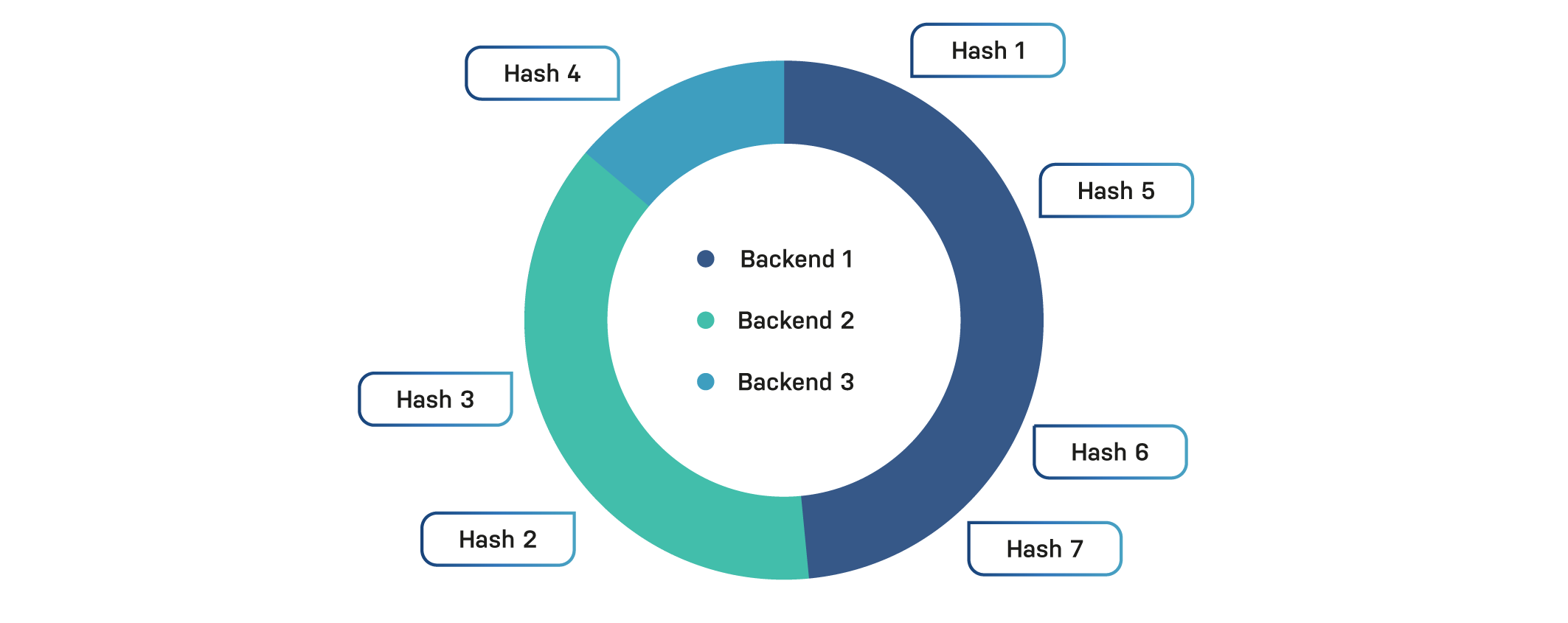
In this case, backend 3 was unlucky, and only has a single hash mapped to it, whereas the other backends each have at least two hashes. This example only uses a single replica.
When the .backend() method is called, the smallest hash value larger
than the hash itself is looked up on the circle. The movement is
clockwise and may wrap around the circle. The backend that has the
corresponding hash on its surface is selected.
When a backend is out of commission, its keys are remapped to other nodes while it is unavailable. When the backend becomes healthy again, it will receive its original hashes again.
Because a level of randomness is introduced, certain backends may be linked to a lot of hashes, whereas other backends aren’t. This results in a higher load on a single backend and less fairness. In the chart above, backend 3 has four out of seven hashes it takes care of.
By increasing the number of replicas per backend, every backend has more occurrences on the ring, which results in a fairer distribution. The default value for the shard director is 67.
But for the sake of simplicity, here’s an example with five replicas:
As you can see the distribution is a lot fairer. Of course this doesn’t matter for seven hashes, but as the hash count increases, the effect of replication does as well.
A simple simulation with three backends using a single replica and 100 total requests yielded the following results:
This ratio is represented in the first pie chart.
When we increased the replica count to 67, the following results came back:
This is somewhat better and represents the ratios in the second pie chart. When we increased the replica count to 250, the distribution was even more equal:
Although equidistribution is nice, it comes at a cost. The more replicas you define, the higher the CPU cost with diminishing returns.
You can configure the replica count in the .reconfigure() method.
Here’s some example VCL that sets the replica count to 50:
sub vcl_init {
new vdir = directors.shard();
vdir.add_backend(backend1);
vdir.add_backend(backend2);
vdir.add_backend(backend3);
vdir.reconfigure(50);
}
The least connections director is not part of vmod_directors but is
a dedicated VMOD that is part of Varnish Enterprise.
It will route backend connections to the one with the least amount of connections at that point. An optional ramp-up configuration is also available.
Just like the random director, this one also uses weights to prioritize traffic to specific backends.
Here’s some example VCL to illustrate how to use vmod_leastconn:
vcl 4.1;
import leastconn;
backend backend1 {
.host = "backend1.example.com";
.port = "80";
}
backend backend2 {
.host = "backend2.example.com";
.port = "80";
}
backend backend3 {
.host = "backend3.example.com";
.port = "80";
}
sub vcl_init {
new vdir = leastconn.leastconn();
vdir.add_backend(backend1, 1);
vdir.add_backend(backend2, 1);
vdir.add_backend(backend3, 1);
}
sub vcl_recv {
set req.backend_hint = vdir.backend();
}
And here’s a VCL snippet where a one-minute rampup is used for backends that have become healthy:
sub vcl_init {
new vdir = leastconn.leastconn();
vdir.rampup(1m);
vdir.add_backend(backend1, 1);
vdir.add_backend(backend2, 1);
vdir.add_backend(backend3, 1);
}
This means that when an unhealthy backend becomes healthy again, its weight is initially reduced, and gradually increases, until the configured weight is reached. In the example above, the weight increase happens over the course of a minute.
Remember vmod_goto, the VMOD that supports dynamic backends?
The goto.dns.director() function exposes a director object and
fetches the associated IP addresses from the hostname. If multiple IP
addresses are associated, Varnish cycles through them and performs
round-robin load balancing.
Imagine having a pool of origin servers that is available via
origin.example.com with the following IP addresses:
192.168.128.2
192.168.128.3
192.168.128.4
The VCL example below will extract these IP addresses via DNS and will perform round-robin load balancing:
vcl 4.1;
import goto;
backend default none;
sub vcl_init {
new apipool = goto.dns_director("origin.example.com");
}
sub vcl_recv {
set req.backend_hint = apipool.backend();
}
If you remember the strengths of vmod_goto from previous chapters,
you’ll understand that DNS resolution is not done at compile time but
at runtime.
This means that if the hostname changes, vmod_goto will notice these
changes and act accordingly. This way you can scale out your web server
farm without having to reconfigure Varnish.
However, it is important to take DNS TTLs into account. A refresh of
the hostname will only happen if the TTL has expired. DNS records have
TTLs, and they can be quite high. You can also define a TTL in
goto.dns_director(). Which one is considered?
The standard behavior is that vmod_goto will resolve the hostname
every ten seconds. This can be overridden via the ttl argument.
You can also define a TTL rule in which you define to what extent the TTL from the DNS record is respected.
These are the possible values:
abide: use the TTL that was extracted from the DNS recordforce: use the TTL parameter that was defined by vmod_gotomorethan: use the TTL from the DNS record unless the TTL
parameter is higherlessthan: use the TTL from the DNS record unless the TTL
parameter is lowerHere’s a VCL snippet where we enforce a 30-second TTL unless the TTL extracted from the DNS record is less than 30 seconds:
sub vcl_init {
new apipool = goto.dns_director("origin.example.com", ttl=30s, ttl_rule=lessthan);
}