The entire concept of caching is not an afterthought in HTTP. As the protocol evolved, specific headers were introduced to support caching.
However, there’s always a difference between the specification and the implementation of the protocol.
Originally, HTTP’s caching headers were designed for browser caching. But experience has taught us, this is not a reliable solution:
Luckily, reverse caching proxy servers like Varnish can also interpret these caching headers. These are shared caches, and HTTP even has specific semantics to control these sorts of caches.
The fact that these headers exist allows for caching policies to become portable: they are part of the code, they are part of a conventional specification, and they should be respected by any kind of caching device or software. This reduces vendor lock-in while allowing developers to better express their intentions.
Let’s have a look at these headers, and see how they allow you to cache.
The Expires response header isn’t really an exciting header. It’s also
quite limited in its usage. Here’s an example:
Expires: Wed, 1 Sep 2021 07:28:00 GMT
The idea is that a response containing this header can be stored in cache until September first 2021 at 07:28 (GMT time zone). Once that time is reached, the cached object is considered stale and should be revalidated.
There’s not a lot of nuance to it:
Although Varnish supports this header, it’s not that common. You’re better off using the
Cache-Controlheader instead.
Some servers will convey that a response isn’t cacheable by setting an
Expires at the beginning of the Unix Time:
Expires: Thursday, 1 January 1970 00:00:00 GMT
Expireshas been deprecated since HTTP/1.1 and should be avoided. If both aCache-Controlheader and anExpiresheader are present,Expiresis ignored. ### The Cache-Control header
The Cache-Control header is the main tool in your toolbox when it
comes to controlling the cache. Compared to Expires, the semantics of
Cache-Control are a lot broader, as it is actually a list of
finer-grained properties.
The primary expectation of any caching header is to indicate how long a
response should be cached. Implicitly this also allows you not to cache
certain responses. Cache-Control also has the capabilities to express
what should happen when an object has expired.
The
Cache-Controlheader is both a request and a response header. We commonly use it as a response header to describe how caching the response should be approached. But a browser can also send aCache-Control: no-cacheto indicate that it doesn’t want to receive a cached version of a response.
The first example features both max-age and s-maxage:
Cache-Control: s-maxage=86400, max-age=3600
max-age is aimed at browsers. In this example, a browser can cache the
response for an hour, which corresponds to 3600 seconds because of the
max-age=3600 keyword.
s-maxage, however, is aimed at shared caches like Varnish. In this
example, Varnish is allowed to cache the response for a day because of
the s-maxage=86400 keyword.
If Varnish sees the
s-maxagekeyword, it will take that value as the TTL. If there’s nos-maxage, Varnish will use themax-agevalue instead.
The public keyword indicates that both shared and private caches
(browsers) are allowed to store this response in cache. Here’s an
example:
Cache-Control: public, max-age=3600
In this example, both the browser and Varnish are allowed to cache the response for an hour.
The private keyword, on the other hand, prohibits shared caches from
storing the response in cache:
Cache-Control: private, max-age=3600
The example above only allows browsers to cache the response for an hour.
The Cache-Control header offers many ways of indicating that a
response should not be cached:
Cache-Control: s-maxage=0
This example uses a zero TTL to keep a response from being cached. It also works with max-age:
Cache-Control: max-age=0
If you just want to avoid that a shared cache stores the response,
issuing private will do:
Cache-Control: private
And then there’s the well-known no-cache and no-store keywords:
Cache-Control: no-cache, no-store
no-cache means that the data in cache shouldn’t be used without a
systematic revalidation: the agent always needs to verify that the
cached version is the current one.no-store means that the object shouldn’t even be stored in cache,
let alone be served from cache.The
no-cacheandno-storekeywords each have their own nuance, but most of the time they have the same effect, depending on the implementation.
When a cached object expires, it’s up to the cache to revalidate the content with the origin server.
In its simplest form, a request to an expired object will trigger a synchronous backend fetch and will update the object.
Some implementations, including Varnish, support asynchronous revalidation. This implies that stale content is served while the new content is asynchronously revalidated.
The Cache-Control header has a couple of ways of expressing what
should happen when an object expires, and how revalidation should
happen.
Take this header for example:
Cache-Control: public, max-age=3600, stale-while-revalidate=300
This response can be stored in cache for an hour, but when it expires, the cache should serve the expired object for a maximum of 300 seconds past its expiration time, while backend revalidation takes place. As soon as the revalidation is finished, the content is fresh again.
Varnish’s stale while revalidate implementation is called grace mode and is covered later in this chapter.
Another revalidation mechanism is based on the must-revalidate
keyword, as illustrated in the example below:
Cache-Control: public, max-age=3600, must-revalidate
In this case, the content is fresh for an hour, but because of
must-revalidate, serving stale data is not allowed. This results in
synchronous revalidation once the cached object has expired.
A third revalidation mechanism in Cache-Control is one that is a bit
more aggressive:
Cache-Control: public, no-cache
Although no-cache was already discussed earlier as a mechanism to
prohibit a response from being cached, its actual purpose is to force
revalidation without explicit eviction.
It implies must-revalidate, but also immediately considers the object
as stale.
First things first: Varnish doesn’t respect the Cache-Control as a
request header, only as a response header.
Your web browser could send a Cache-Control: no-cache request header
to avoid getting the cached version of a page.
One could argue that if Varnish truly wants to comply with HTTP’s specs, it would respect this header, and not serve content from cache. But that would defy the entire purpose of having a reverse caching proxy, and this could result in a severe decline in performance and stability, not to mention an increased attack surface.
With that out of the way, let’s look at which Cache-Control features
Varnish does support by default:
s-maxage and sets its TTL according to this
value.max-age and sets its TTL according to this value,
unless a s-maxage directive was found.private directive and will not cache if it
occurs.no-cache directive and will not cache if it
occurs.no-store directive, and will not cache
when it occurs.max-age or s-maxage to zero will cause Varnish not to
cache the response.stale-while-revalidate and will set
its grace time accordingly.There are two common Cache-Control directives that Varnish ignores:
publicmust-revalidateThere is a
must-revalidateVarnish implementation in the making, but since this would result in a breaking change, it can only be introduced in a new major version of Varnish.must-revalidatesupport in Varnish would result in grace mode being disabled.
The Edge Architecture Specification, which is a W3C standard, defines the use of surrogates. These surrogates are intermediary systems, that can act on behalf of the origin server.
These are basically reverse proxies like Varnish. Although some of them might be located close to the origin, others might be remote.
Varnish’s typical use case in this context, is as a local reverse caching proxy. A typical example of remote reverse caching proxies is a content delivery network (CDN).
Varnish is also CDN software. Although Varnish is primarily used in a local context, there are many use cases where Varnish is used in various geographical points of presence, to form a full-blown CDN.
In chapter 9, we’ll discuss how Varnish can be used to build your own CDN.
Whereas a regular proxy only caches content coming from the origin, a surrogate can act on behalf of the origin and can perform logic on the edge. From offloading certain logic, to adding functionality on the edge, this makes surrogates a lot more powerful than regular proxies.
Surrogates can be controlled through specific HTTP headers:
Surrogate-Capability header is a request header, sent by the
surrogate to announce its capabilities.Surrogate-Control header is a response header, sent by the
origin, to control the behavior of the surrogate, based on the
capabilities it announced.The Surrogate-Capability header is a request header that is not sent
by the client, but by the surrogate itself. This header announces the
surrogate capabilities that this reverse proxy has.
The origin that receives this header can act on these capabilities, and
later control some of these surrogate capabilities through the
Surrogate-Control header.
A Surrogate-Capability header is a collection of unique device
tokens. Each one of these tokens relates to a specific surrogate that
can be used to announce its own capabilities.
One of the most common surrogate capabilities is the capability to process edge-side includes.
An edge-side include is a markup tag that is used to assemble content on the edge, using a source attribute that refers to an HTTP endpoint.
When an origin server sends such an ESI tag, the surrogate will process the tag, call the endpoint, potentially cache that HTTP resource, and assemble the content as a single HTTP response.
Here’s how a surrogate can announce ESI support:
Surrogate-Capability: varnish="ESI/1.0"
Once a surrogate has announced its capabilities, the origin can
control it using a list of directives in the Surrogate-Control header.
When we use our ESI example, this is how the origin would specify how the origin should process any ESI tags in the response:
Surrogate-Control: content="ESI/1.0"
And this is what an ESI tag looks like:
<esi:include src="http://example.com/header/" />
Surrogate-Control response header instructs the surrogate to
process these tags as ESI. In chapter 4 we’ll discuss ESI in more
detail.Although surrogates are about additional capabilities that go beyond
basic HTTP, there is still a caching component to it. A
Surrogate-Control header can contain directives like no-store and
max-age, which are used to control the cacheability of a response.
Surrogates can use the Surrogate-Control header to set the
cacheability of a response and its TTL. The requirement is that a
Surrogate/1.0 capability token is set in the Surrogate-Capability
header, as illustrated below:
Surrogate-Capability: varnish="Surrogate/1.0"
When a surrogate announces Surrogate/1.0 support, the
Surrogate-Control caching directives have precedence over any TTL
defined using the Cache-Control or Expires header.
Here’s an example where we combine caching and ESI control:
Surrogate-Control: no-store, content="ESI/1.0"
Regardless of any Cache-Control header, the response will not be
cached, but the output will be parsed as ESI.
It’s also possible to indicate how long a surrogate should cache a response:
Surrogate-Control: max-age=3600
In the example above, a surrogate may cache this response for an hour.
But it can get a bit more complicated when you look at the max-age
syntax in the following example:
Surrogate-Control: max-age=3600+600
This Surrogate-Control example directs the surrogate to cache the
response for an hour, but allows stale content to be served for another
ten minutes, while revalidation happens.
Although it’s nice to have revalidation features within the
Surrogate-Controlsyntax, it diverges from the conventionalstale-while-revalidatesyntax that is part of theCache-Controlheader.
There’s even an extra directive to control caching behavior, and that’s
the no-store-remote directive. no-store-remote will instruct remote
caches not to store a response in cache, whereas local caches are
allowed to store the response in cache.
The implementation of
no-store-remoteis a bit arbitrary, and depends on whether or not a surrogate considers itself a remote cache or a local cache. It’s up to the surrogate to decide, but generally, surrogates that are more than one or two hops from the origin server can call themselves remote. In most cases, CDNs fit that description.
Here’s an example of no-store-remote:
Surrogate-Control: no-store-remote, max-age=3600
In this example, local caches with surrogate capabilities are allowed to cache the response for an hour, whereas remote caches aren’t allowed to store this response in cache.
The idea behind surrogates is that they can be deployed in various locations and can be part of a tiered architecture. When using a mixture of CDNs and local caches, various devices can have various capabilities.
Targeting specific surrogate devices is important when you want to control their individual capabilities. Each device emits its own device keys containing their individual capabilities.
Devices that are further along the chain may append capabilities to the
Surrogate-Capability header as long as the device key remains
unique.
Here’s such an example:
Surrogate-Capability: varnish="Surrogate/1.0 ESI/1.0", cdn="Surrogate/1.0"
In this case, a device named varnish supports both the Surrogate/1.0
specification and has ESI capabilities. There’s also a device named
cdn that only supports Surrogate/1.0.
These values were appended to the Surrogate-Capability header by the
various surrogates in the content delivery chain and will be
interpreted by the origin.
The origin can then issue the following Surrogate-Control header to
control both devices:
Surrogate-Control: max-age=60, max-age=86400;varnish, max-age=3600;cdn, content="ESI/1.0";varnish
Let’s break this down:
max-age=60).varnish will store the response in
cache for a day (max-age=86400;varnish).cdn will store the response in cache
for an hour (max-age=3600;cdn).varnish surrogate device also has to process one
or more ESI tags in this response.Here’s another combined example:
Surrogate-Control: max-age=3600, max-age=86400;varnish, no-store-remote
And here’s the breakdown:
max-age=3600).varnish will store the response in
cache for a day (max-age=86400;varnish).no-store-remote).Out-of-the-box, Varnish’s support for surrogates is very limited. However, because capabilities and controlling features are so diverse, there is no one-size-fits-all solution. The VCL language is the perfect fit for the implementation of custom edge logic.
Varnish does respect the Surrogate-Control: no-store directive in its
built-in behavior. Any other behavior should be declared using VCL.
In chapter 8, we’ll be talking about decision-making on the edge, which is exactly the goal of surrogates.
There’s the Expires header, there’s the Cache-Control header, and
within Cache-Control there’s max-age and s-maxage. Plenty of ways
to set the TTL, but what is the order of precedence?
Cache-Control header’s s-maxage directive is checked.s-maxage, Varnish will look for max-age to set
its TTL.Cache-Control header being returned, Varnish will
use the Expires header to set its TTL.default_ttl
runtime parameter as the TTL value. Its default value is 120
seconds.vcl_backend_response, letting you
change the TTL.set beresp.ttl will get the
upper hand, regardless of any other value being set via response
headers.You’ve probably heard the term idempotence before. It means applying an operation multiple times without changing the result.
In math, multiplying by zero has that effect. But in our case, we care about idempotent request methods.
An HTTP request method explicitly states the intent of a request:
GET request’s purpose is to retrieve a resource.HEAD request’s purpose is to only retrieve the headers of a
resource.POST request’s purpose is to add a new resource.PUT request’s purpose is to update a resource.PATCH request’s purpose is to partially update a resource.DELETE request’s purpose is to remove a resource.This should sound quite familiar if you’ve ever worked with RESTful APIs.
The only idempotent request methods in this list are GET and HEAD
because executing them does not inherently change the resource.
This is not the case with POST, PUT, PATCH, and DELETE.
That’s why Varnish only serves objects from cache when they are
requested via GET or HEAD.
Caching non-idempotent requests is possible in Varnish, but it’s not conventional behavior. Using custom VCL code and some VMODs, it can be done. But it depends heavily on your use case. See chapter 8 for a section about caching POST requests.
Note: because of HTTP’s flexibility, you can of course design idempotent
POSTrequests and non-idempotentGETones, but the REST approach is the overwhelming norm.
As described in the previous section: when receiving a client request, a reverse caching proxy should be picky as to what request methods it deems cacheable.
The same thing applies for backend responses: only backend responses containing certain status codes are deemed cacheable. These are all defined in section 6.1 of RFC 7231.
Varnish only caches responses that have the following status code:
200 OK203 Non-Authoritative Information204 No Content300 Multiple Choices301 Moved Permanently302 Moved Temporarily307 Temporary Redirect304 Not Modified404 Not Found410 Gone414 Request-URI Too LargeResponses containing any other status code will not be cached by default.
Throughout this chapter, we talk about HTTP, and more specifically in this section, about the caching aspect of it. Through a variety of headers, we can instruct Varnish what to cache and for how long.
But there’s another instruction we can assign to a cache: how to store the object. A cached object should be retrieved through its unique identifier. From an HTTP perspective, each resource already has a conventional way to be identified: the URL.
HTTP caches like Varnish will use the URL as the hash key to identify an object in cache.
If the URL is the unique identifier, but the content differs per user, it seems as though you’re in trouble, and the response will not be cached. But that’s not really the case because HTTP has a mechanism to create cache variations.
Cache variations use a secondary key to identify variations of the object in cache.
It’s basically a way for the origin to add information to the hash key to complement the cache’s initial hashing.
The way HTTP requests a cache variation is through the Vary response
header. The value of this Vary header should be a valid request
header.
For each value of the request header that is used in the Vary
response header , a secondary key will be created to store the
variation.
A very common example: language detection.
Although in most cases, splash pages with a language selection option are used for multilingual websites, HTTP does provide a mechanism to automatically detect the language of the client.
Web browsers will expose an Accept-language header containing the
language the user prefers. When your website, or API, detects this, it
can automatically produce multilingual content, or automatically
redirect to a language-specific page.
But without a cache variation, the cache is unaware of this multilingual requirement and would store the first occurrence of the page. This will result in a language mismatch for parts of the audience.
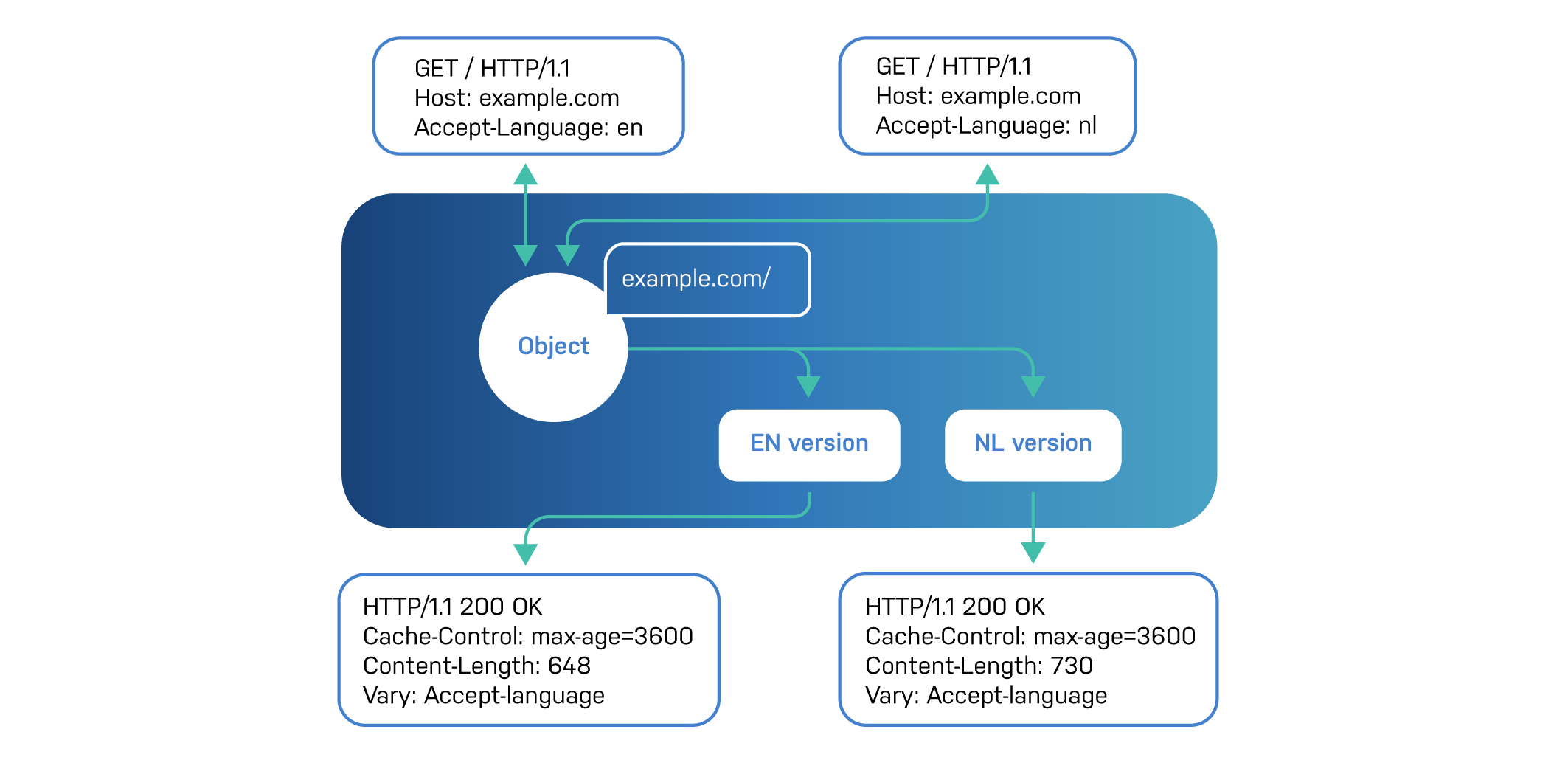
By issuing Vary: Accept-Language, Varnish is aware of the variation
and will create a separate secondary key for each value the
Accept-Language may have.
Disclaimer: this is an oversimplified example. In reality there are more things to consider before creating an
Accept-Languagecache variation, which will be covered in the next section.
One thing to note, which will become important for cache invalidation: variants actually share the hash key, so they can be invalidated in one go.
When dealing with personalized content, you try to cache as much as possible. It may be tempting to jam in cache variations wherever you can.
However, it is important to consider the potential hit rate of each variation.
Take for example the following request:
GET / HTTP/1.1
Host: example.com
Cookie: language=en
The language cookie was set, which will be used to present multilingual content.
You could then create the following cache variation:
Vary: Cookie
There are so many risks involved, unless you properly sanitize the user input.
Problem number one: the user can change the value of the cookie and deliberately, or even involuntarily, increase the number of variations in the cache. This can have a significant impact on the hit rate.
In reality there will probably more cookies than just this language cookie. An average website has numerous tracking cookies for analytics purposes, and the value of some of these cookies can change upon every request.
This means every request would create a new variation. This wouldn’t just kill the hit rate, but it would also fill up the cache to a point that Varnish’s LRU eviction mechanism would forcefully have to evict objects from cache in order to free up space.
That’s why it’s imperative to sanitize user input in order to prevent unwarranted variations.
Because this is what a browser could send in terms of Accept and
Accept-language headers:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-language: nl-NL,nl;q=0.9,en-US;q=0.8,en;q=0.7
It’s very tricky to create variations based on either of those headers because the secondary key that will be created is the literal string value of the varied header.
Without proper sanitization, this will create too many variations, which will drive down your hit rate.
The solution is to clean up the user input using VCL.
We know we’re getting ahead of ourselves here, because VCL will be properly covered in the next chapter. However, it is interesting to know, from a practical point of view, how to properly sanitize user input for these accept headers.
Here’s some example VCL that leverages vmod_accept:
vcl 4.1;
import accept;
sub vcl_init {
new lang = accept.rule("en");
lang.add("nl");
}
sub vcl_recv {
set req.http.accept-language = lang.filter(req.http.accept-language);
}
vmod_accept will simplify the values of Accept-Language to make
variations more controllable. It does this based on a whitelist.
The whitelist is named lang and lists the allowed values for the
Accept-Language header.
By executing the lang.filter() function, vmod_accept will look the
input for the Accept-language header, sent by the browser, and will
keep the first match. If no match is found, the filter will take the
default value.
In this case the allowed values are en and nl. If either of these
languages is found in the Accept-language header, one of them will be
selected, based on the first occurrence. If none of them are found, the
default language will become en.
This is what comes in:
Accept-language: nl-BE;q=0.9,en-US;q=0.8,en;q=0.7
And because the first match is nl-BE, vmod_accept will turn this
into:
Accept-language: nl
You can then safely return a Vary: Accept-language, knowing that only
two variations will be allowed.
This can also be done for other headers, using other modules or VCL constructs.
Unfortunately, it’s not always possible to sanitize the headers you want to vary on. Cookies are a perfect example: you cannot sanitize certain parts for the sake of cache variations. You risk losing valuable data.
A potential solution is to create a custom request header that contains the value you want to vary on.
Imagine the following cookie header:
Cookie: sessionid=615668E0-FC89-4A82-B7C1-0822E4BE3F87, lang=nl, accepted_cookie_policy=1
You want to create a cache variation on the value of the language cookie, but you don’t want to lose the other cookies in the process.
What you could do is create a custom X-Language header that contains
the value of the language cookie. You could then perform the following
cache variation:
Vary: X-Language
Here’s the VCL code to achieve this:
sub vcl_recv {
set req.http.x-language = regsub(req.http.cookie,"^.*lang=([^;]*);*.*$","\1");
if(req.http.x-language !~ "^en|nl$") {
set req.http.x-language = "en";
}
}
The VCL code has a similar effect to the Accept-language
sanitization example:
en and nl values are allowedenAs a developer, you can then opt to vary on X-Language.
This custom variation can also be processed using VCL only, without the need for an explicit cache variation in HTTP.
Here’s the VCL code:
sub vcl_recv {
set req.http.x-language = regsub(req.http.cookie,"^.*lang=([^;]*);*.*$","\1");
if(req.http.x-language !~ "^en|nl$") {
set req.http.x-language = "en";
}
}
sub vcl_backend_response {
set beresp.http.vary = beresp.http.vary + ", x-language";
}
At the end of vcl_backend_response, Varnish will check the vary
header and create the secondary key, as if the header had been provided
by the origin directly.
Although this makes life easier for developers, it’s not a portable solution. We always prefer using HTTP as much as possible and then resort to VCL when HTTP cannot solve the problem.