Varnish Controller
Routers in Varnish Controller are used for traffic routing. The router supports two types of routing:
The router runs as an integrated part of Varnish Controller. The routers will be configured over NATS by brainz and also receive utilization information from agents over NATS. Reconfiguration, updates, health states etc, will automatically be applied to the routers.
Each router must have a unique name that is specified during the startup of the router process. For routers that use different private token (version 5.0+), the name can be the same as long as different tokens are used for the routers.
Note: In this chapter, endpoints, Varnish servers and cache nodes are interchangeable.
An router can have the following states:
Incoming HTTP requests from clients are redirected to the most suitable caching node using the 302 Found HTTP response. Location header is also included containing the URL of the caching node. The original host header is preserved in the redirected URL as part of the path, which makes it possible to route multiple tenants in a shared environment. The caching node can extract the original host header and revert the path back to the original path as needed.
If it is a shared environment where a root VCL is deployed, the root VCL will inject a X-Routed-For header containing the actual host:port it was routed to (this information is taken from the agent’s baseURL). The user’s VCL
can then retrieve this information from the X-Routed-For header.
This routing mechanism is usually suitable for static assets and media streaming, and not for regular web pages. This is because regular web pages will be redirected and the address will often change, but for static assets and media streaming, this will happen transparently to the user. For media streaming, redirect routing is useful to balance load faster.
HTTP routing can be enabled/disabled via the -http-routing flag for the router.
Basic example:
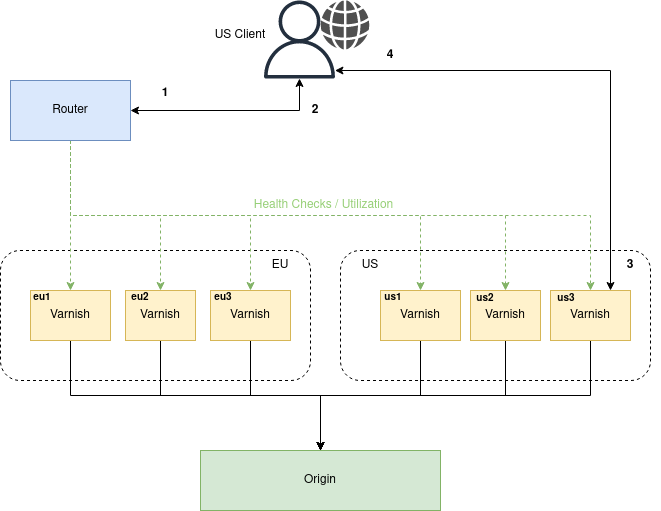
cdn.example.com and has 6 running endpoints (with agents), 3 in the US and 3 in the EU.cdn.example.com points to the router IP.cdn.example.com towards all varnish instances to verify which endpoints are healthy.cdn.example.com configured.us3.example.com with the URL: http://us3.example.com/cdn.example.com/movie.m3u8
cdn.example.com from the first part of the URL and verifies that this domain is configured on the server.cdn.example.com receives the request.In order for the Varnish servers to handle HTTP redirect URLs, the root.vcl which is deployed by Varnish Controller picks out the redirected host and path.
This is handled automatically for shared deployments. For root deployments, this must be manually handled in the VCL.
The Host and URL is not changed to the requested host and URL in the loaded user VCL. Hence, the Host will be the host of the configured BaseURL for the
agent. The path will include the domain (e.g. http://agent1.example.com/mydomain.com/myfile.m3u8). This is subject to change in future releases.
In order to make web browsers happy regarding CORS for HTTP redirect routing, the VCL that is handling the requests must add CORS rules to the backend responses.
Example:
sub vcl_backend_response {
set beresp.http.Access-Control-Allow-Origin = "*";
set beresp.http.Access-Control-Allow-Methods = "GET,HEAD";
}
Starting with Version 6.0.0, Varnish Controller introduces TLS management capabilities, which enable users to conveniently handle TLS certificates. One crucial aspect is the necessity for the Controller to maintain ownership of the Varnish instance. Consequently, loading certificates directly into the Varnish instance is discouraged in order to ensure proper management of the Controller. Instead, users should leverage the TLS management features provided by Varnish Controller.
Incoming DNS requests from clients are directed to the best caching node using dynamic A and AAAA records.
The router acts as a remote backend for PowerDNS. PowerDNS is the DNS server and queries to PowerDNS will be forwarded over a REST API (defined by PowerDNS) towards the router. The router will then respond with the most appropriate cache node’s IP address for the specific DNS request.
This routing mechanism is usually suitable for web and APIs.
DNS can be enabled/disabled via the -dns-routing flag for the router.
Basic example:
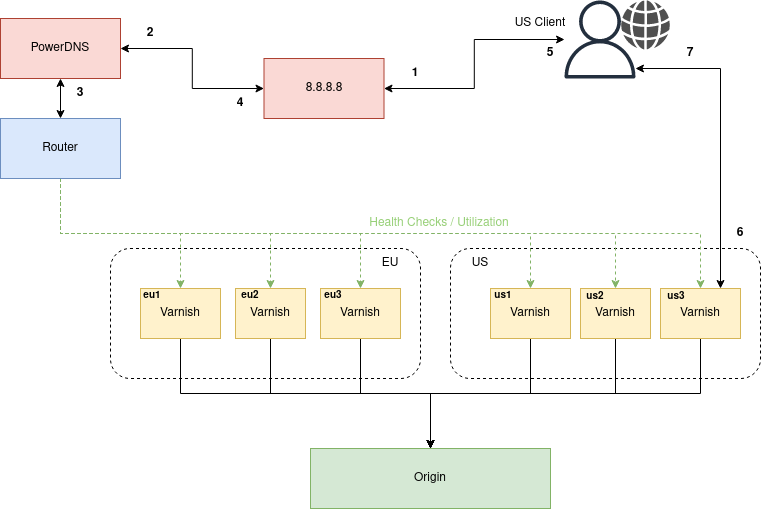
cdn.example.com and has 6 running endpoints (with agents), 3 in US and 3 in EU.cdn.example.com is configured with a VCLGroup and assigned a RoutingRules, with GeoIP routing rule.-ns).cdn.example.com towards all varnish instances to verify which endpoints are healthy.8.8.8.8 in this example) for cdn.example.comcdn.example.com and retrieves the requests.us3 in this case).us3 endpoint is returned back as the A (or AAAA) record.8.8.8.8 that it’s endpoint us3 IP that is the address for cdn.example.com.cdn.example.comus3 endpoint based on the URL such as http://cdn.example.com/movie.m3u8.us3) responds back with the manifest file.Each VCLGroup can have a specific order of routing rules. These are configured via RoutingRules. For each client request the configured routing order will be applied. The first routing decision that returns a matching endpoint will succeed and will be sent back to the client (via HTTP redirect or DNS). If there is no match, the router will try with the next routing decision in the configured routing order.
Example order (evaluated from left to right):
history,geoip,leastutilized,external
If no endpoint is found after all rules have been evaluated, a 503 Service Unavailable will be returned with a RetryAfter header.
The RetryAfter header value (duration) is configurable in the RoutingRules or under HTTP & DNS Settings -> HTTP Routing in the UI.
LeastUtilized is always applied as a fallback rule, and will apply either if no rules are configured, or if no rules return a match.
In the example above, external will only be evaluated if there are no healthy endpoints found for the other rules. If external rule contains no healthy endpoints, leastutilized will be evaluated again (fallback). In this example, it will most likely fail since it was already evaluated and failed before, and a 503 Service Unavailable will be reported back to the client.
Rules that need extra configuration is specified on the CLI with colons, and in the UI with a drop down box.
Colon separated routing decisions such as plugin:1,plugin:2,asn:1,cidr:1,geolocation:1, is based on the naming convention of <type>:<id>.
In the example above, plugin:1 indicate that the plugin with ID 1 should be used.
When adding a gRPC type plugin, the gRPC connection will not be instant and some requests may skip the plugin rule as it’s not yet connected to the gRPC service.
These requests will then fallback to the rule after the plugin or the LeastUtilized fallback rule.
This will look up the client IP in a MaxMind GeoIP database and return lat/lon coordinates. If a successful lookup is made, the geographically closest endpoint to the client’s location will be used. If one or more endpoints are on the same location, the first healthy, not over-utilized endpoint will be selected.
Note that this is the geographical point-to-point distance between cache node and client, and not the closest endpoint in terms of network hops or latency. When using DNS-based routing, geographical distance will be calculated using edns-client-subnet if available, otherwise, it will use recursive resolvers IP for the geographical lookup.
The endpoint locations are configured in the agent configuration in the UI, or directly on the varnish-controller agent configuration, see here for details.
This requires a GeoIP MMDB file to be present and configured on the traffic routers, for details, see here
If no healthy and not over-utilized endpoint is found, then the next routing rule will be evaluated (if any).
Tagged based routing is making use of the tags that the router and the agents have assigned. If the router has the same tag as an agent, the agent’s Varnish server will be selected as the endpoint. This can be used for selecting endpoints at the same location as the router itself.
Matching endpoints will be selected based on configured subdecision (healthy, leastutilized or random). The default is leastutilized.
Note: Prior to version 6.0 of the controller, no subdecision were supported and leastutilized were the default behavior.
If no healthy and not over-utilized endpoint is found, then the next routing rule will be evaluated (if any).
This will select the least utilized endpoint based on utilization reported by the agents. This will return an endpoint even if it is over-utilized.
If no healthy endpoint is found, then the next routing rule will be evaluated (if any).
This is always the fallback rule if no other rule is finding an appropriate endpoint.
Randomly selects one endpoint that is healthy and not over-utilized.
If no healthy and not over-utilized endpoint is found, then the next routing rule will be evaluated (if any).
External routing will use the configured external endpoint with highest weight, if it is healthy. If it is not healthy it will select next based on the weight. The external endpoints are basically redirect URLs or IP addresses that could point to a 3rd party CDN or other type of cache node. If both CNAME and IP (v4/v6) is configured, the CNAME will used for DNS responses.
External routes have no utilization probes and if they are over utilized they should report unhealthy. Hence, how to measure utilization for external endpoints is up to the user.
The location header for the external endpoint can be configured using templates. Default is to redirect to the external routes <BaseURL>/<host>/<path>. From version 5.1 of the controller, this
location header can be configured with a template. The template has a certain set of variables as keywords.
{{.BaseURL}} - The configured BaseURL of the external endpoint (e.g. http://example.com/){{.Host}} - The host that was requested (Domain/FQDN, e.g. domain.com){{.Path}} - The path that was requested (URI, e.g. /my/images/1.png)The default template is {{.BaseURL}}/{{.Host}}{{.Path}}. An example of a different template could be {{.BaseURL}}{{.Path}}?host={{.Host}}. What template
to use depends on the receiving side of the redirect, how the reciever wants to handle the request. It is possible to omit parts such as the {{.Host}}, but the
template needs to resolve in to a valid URL.
If no healthy external endpoint is found, then the next routing rule will be evaluated (if any).
Uses the same endpoint that was selected previously for the same IP address during the configured period of time. Once the history is timed out for the IP address, a new routing decision will be made. This leads to faster lookups of endpoints.
If the existing endpoint in the history is not healthy, is over-utilized or it has timed out (HistoryTTL), then the next routing rule will be evaluated (if any).
The router from version (4.1.0) supports plugins as routing rules. The first available plugin is for gRPC (Google Remote Procedure Call). The router provides a pre-defined Flatbuffer schema that defines the functions for communicating with the gRPC service. The router acts as a client towards the user implemented gRPC server. The gRPC service is something that the user has to implement.
The router sends information (defined in the schema) about available and healthy endpoints, client information and HTTP headers (for HTTP requests). The gRPC service then either responds with an ID of the endpoint to select or a custom result with a redirect URL and IPv4/IPv6 addresses. The router will then perform a HTTP redirect or DNS response based on the gRPC service response. Either with the IPv4/IPv6 or URL that the selected endpoint is configured with, or the information given as a custom response.
The gRPC service can be written in most common languages (Go/C++/C/C#/Java/Kotlin/Javascript/Lua/PHP/Rust/Swift etc.). As long as it is implemented using the Flatbuffer schema provided by the router.
For implementation details of a gRPC routing plugin, see Routing Plugins/gRPC.
The router from version (5.0.0) supports routing based on ASN/CIDR/Geolocations. These decisions are tag based and requires the user to pre-configure the specific decision(ASN/CIDR/Geolocation) to specific tags. From version 5.1.0 the controller also supports routing decision based on regular expressions (HTTP routing only) and reject routing to reject certain requests based on defined conditions.
These decisions does also have the option to set a specific Subdecision. The routing is done to a specific tag, however several endpoints can have the same tag. Subdecision is way to set priority between these endpoints within a tag. Some of them corresponds with the routing decisions that can be set directly within a routing rule defined above.
Looks up the client IP in a MaxMind ASN database to resolve which ASN the client IP belongs to. If a successful lookup is made, the router will check if the client’s ASN is configured to match specific tag(s) and if this is the case, resolve which endpoint within the tag based on Subdecision.
The CIDR decision will check whether the client IP is part of a configured CIDR-Range. If there is a match, the router will check which tag(s) the CIDR-Range is connected to and will resolve the specific endpoint based on Subdecision.
Looks up the client IP in a MaxMind GeoIP database and return a location by name. If a successful lookup is made, the router will check if the configured geolocation matches If there is a match, the router will resolve which endpoint within the tag(s) based on Subdecision.
The RegExp routing decision makes it possible to create Golang (RE2) supported regular expressions. A RegExp decision is created with a header and a matching
regular expression. The regular expression will be matched towards the given headers value. To support matching on URI and method, the special headers RequestURI and Method exists. Other than those, any header is possible to define.
Example:
# This will match all requests that has a User-Agent header
# containing "curl" and route to agents tagged with tag ID 1
vcli regexproutes add test --regexp User-Agent:".*curl.*":1
Please see Routing Decisions Example for a complete example.
Note: This routing decision is only supported for HTTP routing as it will match towards request URI, method and HTTP headers.
Reject routing is used to reject incoming requests to the router. These requests will be rejected based on defined conditions. The reject decision can be configured
to block all HTTP or all DNS requests. It can also be configured to reject using other decision types such as CIDR, ASN, Geolocation, RegExp and Plugin. If a routing decision
is used to reject requests with, these decisions needs to be configured as Reject decisions.
A reject can be configured to return a custom response body, header(s), location, status-code for HTTP. And IPv4/IPv6/CNAME for DNS.
Please see Routing Decisions Example for a complete example.
Routers become Locked when brainz reports wrong unique ID (UID) to them. The brainz UID is created the first time brainz initializes
the database. When routers are started for the first time, brainz will provide them with this UID. The routers will then only
accept configuration from a brainz instance that uses the same UID.
This functionality is to prevent empty/wrong configuration if the database becomes reset or destroyed without backups. Starting brainz with a new database, without any data, would otherwise wipe the configuration from the routers. So in order to avoid this scenario, the router will become locked.
Locked routers will keep running the previously known configuration until unlocked.
Before unlocking a router make sure that the database contains the same settings that should be deployed to the routers. That means, same tags, deployments,
domains, vclgroups, routingrules and that the routers have the same tags as before (if tagged based routing is used). Once this is added to the database (via API/UI/CLI) the router’s UID file can be removed.
The UID file exists in the routers configured base-dir and is called router.uid. Remove the file and then restart the router and the router will become
running again. Brainz will then update the router with correct configuration.
The router has an internal management interface. A very simple API that supports health checks for the router, health checks for specific domains and prometheus statistics output. The management interface is usually used for debugging purposes only. More detailed information can be retrieved via the Varnish Controller REST API.
Management API endpoints:
/metrics - Prometheus metrics output/health?domain=<domain> - Check health for a given domain, returns 200 OK if the domain has at least one healthy endpoint, else 503 Service Unavailable./live- Always responds 200 OK to verify that the router is up and running.The management interface can be enabled/disabled via the -enable-mgmt flag to the router.
Each router will perform health checks towards the configured domains. The health checks are performed towards each agent’s configured -base-url. The host is specified
for the configured domain and the method and path as per RoutingRule configuration. The health checks can be configured with custom headers that will be included in the
health check requests made by the router.
Example:
Method: GET
HOST: mydomain.com
URL: http\://agent1.example.com/ping
Status of the health checks can be retrieved via the Varnish Controller REST API, CLI and GUI.
In order to verify that routing works as expected it is possible to perform dry run lookups towards the routers via API, CLI and GUI. These traces are not accounted for in the statistics for the routers. The router trace will show information about decisions made, endpoints routed to, client information, geo-ip information (if applicable), timing information etc.
The trace will be performed as it was originating from the specified IP, which makes it possible to see routing decisions for the given IP address. The result can of course vary depending on health, routing order, routing types and utilization.
Example using the CLI:
$ vcli router trace 123.1.1.1 example.com
+---------+-----------+-------------+--------+---------+------------+-----------------------+-----------+------+-------+
| Router | ClientIP | Domain | Agent | Type | LookupTime | URL | IPv4 | IPv6 | Error |
+---------+-----------+-------------+--------+---------+------------+-----------------------+-----------+------+-------+
| router1 | 123.1.1.1 | example.com | ag1(1) | history | 4.879µs | http://127.0.0.1:8091 | 127.0.0.1 | | |
+---------+-----------+-------------+--------+---------+------------+-----------------------+-----------+------+-------+